수년 동안 우리는 시스템을 구축할 수 있는 더 좋은 방법을 찾고 있습니다. 이전에 무엇을 했는지, 새로운 기술을 채택하고, 기술 회사의 새로운 물결이 어떻게 고객과 개발자들이 모두 행복하게 하는 IT시스템을 만들기 위한 다양한 방법을 운영하는지를 관찰했습니다.
Eric Evans의 책 Domain-Driven Design(Addison-Wesley)은 우리 코드에서 실제 세계를 표현하는 중요성을 이해하고, 우리 시스템을 더 좋은 방법으로 모델링하는 것을 보여주었습니다. 지속적인 배포(continuous delivery) 개념은 소프트웨어를 보다 효과적이고 효율적으로 상용 환경에 가져오는 방법을 보여주었고, 모든 체크인을 릴리즈 후보로 다루어야 한다는 아이디어를 우리가 가지게 했습니다. 웹이 어떻게 동작하는지에 대한 이해는 기계와 기계 사이에서 대화하는 더 좋은 방법을 개발하게 했습니다. Alistair Cockburn의 6각형 아키텍처 개념은 비즈니스 로직이 숨어 있는 Layered Architecture에서 우리가 멀어지게 했습니다. 가상화 플랫폼은 인프라 자동화를 통해 머신의 규모를 다루는 방법을 우리에게 제공하여 프로비저닝과 리사이즈를 가능하게 했습니다.
아마존과 구글과 같은 일부 대규모의 성공적인 조직들은 서비스의 전체 수명 주기를 소유한 소규모 팀의 견해를 지지했습니다. 그리고 더 최근에, Netflix는 불과 10년 전만 해도 이해하기 힘든 거대한 규모의 단단한 시스템을 구축하는 방법을 공유했습니다.
- Domain-Driven Design
- Continuous Delivery
- On-Demand Virtualization (주문형 가상화)
- Infrastructure automation
- Small autonomous teams
- Systems at scale
마이크로서비스가 이 세상에 등장했습니다.
사실 마이크로서비스는 전에 발명되거나 설명된 것은 아닙니다. 실제 세상에서 사용함으로써 트렌드나 패턴으로 등정했습니다. 그러나 마이크로서비스는 이전에 있었던 모든 것들 때문에 존재합니다.
이 책을 통해서 마이크로서비스를 구축, 관리, 발전시키는 방법에 대한 그림을 그리는데 도움을 주어 이러한 최우선 업무에서 뛰어나게 할 것입니다.
많은 조직에서 잘 나누어진 마이크로서비스 아키텍처를 채택함으로써 소프트웨어를 빠르게 제공하고 새로운 기술들을 채택할 수 있었습니다.
마이크로서비스는 우리에게 더 자유롭게 반응하고 다른 의사 결정을 내려서 우리 모두에게 영향을 미치는 피할 수 없는 변화에 더 빠르게 대응할 수 있게 합니다.
What Are Micoservices?
마이크로서비스는 함께 동작하는 작고, 자율적인 서비스입니다. 이 정의를 좀 더 세분화하고 마이크로서비스를 다르게 하는 특성들에 대해서 고려해 보겠습니다.
Small, and Focused on Doing One Thing Well
(작고, 한가지를 잘하는 것에 집중)
코드베이스는 우리가 새로운 기능들을 추가하는 코드를 작성할 때 커집니다. 시간이 지남에 따라, 코드베이스가 커지기 때문에 어디를 변경해야 하는지 알기 어려워질 수 있습니다. 명확하고, 모듈화된 단단히 짜여 하나로 된(monolithic) 코드베이스 추진에도 불구하고, 이러한 제멋대로인 프로세스 내 경계가 너무 자주 파괴됩니다. 유사한 함수와 관계된 코드가 널리 퍼지기 시작하고, 버그 수정이나 프로그램 구현이 더 어려워집니다.
모놀리스 시스템에서 우리는 종종 추상화를 하거나 모듈화를 하여 코드가 더 응집되어 있는지를 확인하려고 노력함으로써 이러한 세력에 대항하여 싸웁니다.
관련 코드를 그룹으로 묶는 응집(Cohesion)은 마이크로서비스에서 중요한 개념입니다. 이것은 Robert C. Martin의 '단일 책임 원칙의 정의(Definition of the Single Responsibility Principle)'에 의해 강화되었습니다. "동일한 이유로 변경되는 것들을 함께 모아서 다른 이유로 변경되는 것들을 분리하라"라고 말하고 있습니다.
마이크로서비스는 독립적인 서비스에도 동일한 접근방식을 사용합니다.
우리는 주어진 기능 조각에 대한 살아있는 코드가 어디에 있는지를 명확하게 함으로 서비스 경계를 비즈니스 경계에 초점을 맞춥니다. 그리고 이 서비스가 분명한 경계에 초점을 유지함으로써, 서비스가 너무 커지는 유혹을 피할 수 있습니다. 이것이 소개할 수 있는 연관된 모든 어려움입니다.
제가 자주 묻는 질문은 작은 것이 얼마나 작습니까?라는 것입니다.
코드 라인수가 문제라면, 일부 언어는 다른 언어보다 더 표현력이 우수하므로 더 적은 라인에서 더 많은 일을 수행할 수 있습니다. 또한, 많은 코드 라인은 여러 의존성을 끌어낼 수 있다는 사실도 고려해야만 합니다. 더욱이, 도메인 중 일부는 당연히 복잡해서 더 많은 코드가 필요할 수 있습니다.
호주 RealEstate.com의 Jon Eaves는 특별한 맥락에서 의미가 있는 경험과 상식에 입각하여 마이크로서비스는 2주만에 다시 작성할 수 있는 어떤 것으로 특징지었습니다. 제가 드릴 수 있는 흔한 또다른 대답은 충분히 작고, 더 작아질 수 없다는 것입니다.
컨퍼런스에서 발표할 때, 너무 크고 쪼개고 싶어하는 시스템을 가진 사람이 누구냐고 거의 항상 묻습니다. 거의 모든 사람들이 손을 듭니다. 우리는 너무 큰 것이 무엇인지 잘 알고 있는 것처럼 보이기 때문에 코드 한 조각이 너무 크다고 더 이상 느껴지지 않을 때, 그것은 충분히 작다고 주장할 수 있습니다.
얼마나 작은가에 대해 대답하는데 도움이 되는 강력한 요소는 얼마나 서비스가 팀 구조와 맞춰져 있는가 입니다. 만약 코드베이스가 작은 팀이 관리하기에는 너무 크다면, 부수는 것을 생각해 보는 것이 매우 현명합니다. 나중에 조직 조정에 대해서 더 이야기할 것입니다.
작은 것이 충분히 작아졌을 때, 이런 측면에서 생각하고 싶습니다. : 서비스가 더 작아질수록 마이크로서비스의 장점과 단점을 극대화할 수 있다.
서비스가 더 작아질수록, 독립성 관점에서 장점이 증가합니다.
하지만, 점점 더 많은 가동부(moving parts)를 가지고 있음으로 드러나는 복잡성도 또한 커지는데 이 책을 통해서 탐구할 것입니다. 이러한 복잡성을 더 잘 처리할수록, 점점 더 작은 서비스를 위해 노력할 수 있습니다.
Autonomous
(자율적인?)
마이크로서비스는 분리된 개체입니다. PAAS(Platform As A Service)에 격리된 서비스로 배포되거나 그 자체로 OS(Operating System) 프로세스일 수 있습니다. 비록 오늘날 머신의 정의가 꽤나 흐릿하지만 동일한 머신에 여러 개의 서비스를 패키지하는 것을 피하려고 합니다. 나중에 논의하겠지만, 비록 이러한 격리로 인해 약간의 오버헤드가 추가될 수 있지만, 단순성의 결과는 분산 시스템의 추론을 훨씬 더 쉽게 하고, 더 새로운 기술들이 이러한 형태의 배포와 관련된 많은 문제들을 완화할 수 있습니다.
서비스 간의 모든 커뮤니케이션은 서비스 간의 분리를 강화하고 긴밀한 결합의 위험을 피하기 위해서 네트워크 호출을 통해 이루어집니다.
이러한 서비스는 서로 독립적으로 변경될 수 있어야 합니다. 그리고 소비자의 변경 요구 없이 스스로 배포되어야 합니다. 우리의 서비스가 무엇을 노출해야 하고, 무엇을 숨겨야 하는지를 생각할 필요가 있습니다. 너무 많이 공유하면 소비하는 서비스가 내부 표현과 연결되게 됩니다. 이것은 자율성을 감소시켜서 변경 사항이 발생할 때, 소비자와의 추가적인 조정이 필요하게 됩니다.
서비스는 API(application programming interface)를 노출하며, 협업 서비스들은 이러한 API를 통해 우리 서비스와 통신합니다. 우리는 또한 어떤 기술이 소비자와 연결되지 않도록 하는데 적합한지에 대해 생각할 필요가 있습니다. 이것은 기술 선택에 제약을 주지 않기 위해서 기술과 무관한 API를 선택하는 것을 의미할 수 있습니다. 이 책에서 좋은, 연결되어 있지 않은 API의 중요성에 대해서 몇 번이나 다시 돌아올 것입니다.
디커플링(decoupling)이 없으면-분리되지 않으면, 모든 것이 무너집니다. 황금률 : 다른 것은 변경 없이 서비스 그 자체만을 변경하고 배포할 수 있는가? 대답이 'no'라면 우리가 이 책을 통해서 논의하고자 하는 많은 장점들이 달성하기 어렵게 될 것입니다.
디커플링을 잘 하기 위해서는 서비스를 올바르게 모델링하고 API를 올바르게 얻어야 합니다. 그 부분에 대해서 많은 이야기를 할 것입니다.
Key Benefits
(주요 이점들)
마이크로서비스의 이점은 많고 다양합니다. 이러한 많은 장점들은 분산 시스템의 문에 놓여질 수 있습니다. 그러나 마이크로서비스는 첫째로 분산 시스템과 SOA 개념을 얼마나 멀리 가지고 가는지에 따라 이러한 장점들을 더 많이 달성하는 경향이 있습니다.
Technology Heterogeneity
(기술 이질성)
여러 개의 협업하는 서비스들로 구성된 시스템에서 각각의 내부에 서로 다른 기술을 사용하기로 결정할 수 있습니다. 이것은 더 표준화되고, 종종 마지막에 최하위의 공통분모가 되도록 하는 널리 적용되도록 만든(one-size-fits-all) 접근방법을 선택하는 것보다 각각의 작업에 적합한 올바른 툴을 정할 수 있게 합니다.
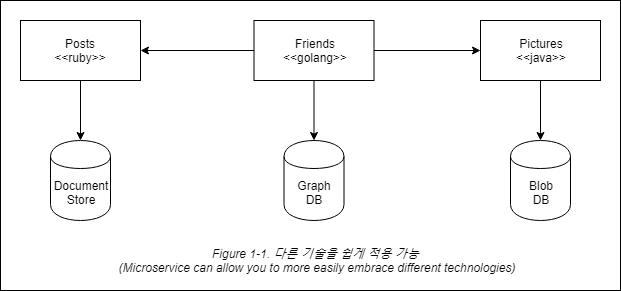
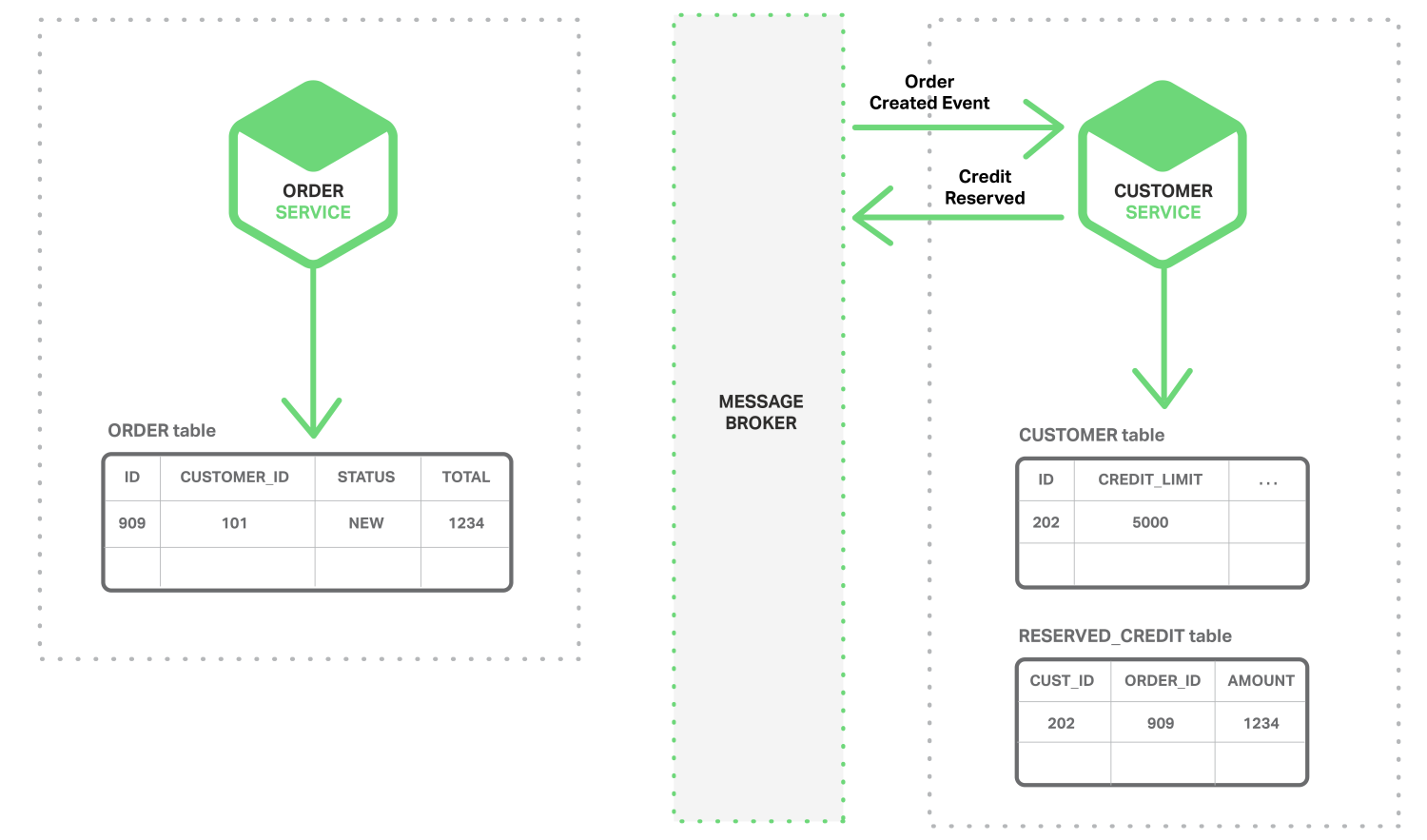
시스템의 일부가 성능을 개선할 필요가 있다면, 필요한 성능 수준을 더 잘 달성할 수 있는 다른 기술 스택을 사용하기로 결정할 수 있습니다. 또한 시스템의 다른 부분의 변경에 필요한 데이터를 어떻게 저장할지를 결정할 수 있습니다. 예를 들면, 소셜 네트워크의 경우, 소셜 그래프의 상호 연관성을 높게 반영하기 위해 사용자의 상호작용을 그래프 기반 데이터베이스에 저장할 수 있습니다. 그러나 아마도 사용자가 만든 게시물은 문서 기반 데이터 저장소에 저장할 수 있으므로, 그림 1-1에 보이는 것처럼 이기종 아키텍처가 떠오르게 됩니다.
마이크로서비스를 통해 기술을 보다 빠르게 받아들일 수 있고, 새로운 발전이 어떻게 우리를 도와주는지를 이해할 수 있습니다. 새로운 기술을 시도하고 채택하는데 있어서 가장 큰 장벽 중 하나는 그와 관련된 위험입니다. 모놀리틱(monolithic) 어플리케이션에서 새로운 프로그래밍 언어, 데이터베이스, 혹은 프레임워크를 시도하고 싶다면, 그 변화는 시스템의 많은 부분에 영향을 미치게 됩니다. 여러 서비스로 이루어진 시스템에서는 새로운 기술을 시도해 볼 수 있는 여러 새로운 장소가 있습니다. 잠재적인 부정적 영향을 제한할 수 있다는 것을 알기 때문에 아마도 가장 위험이 적은 서비스를 선택해서 기술을 사용할 것입니다. 많은 조직에서는 신기술을 보다 빠르게 흡수하여 실제 이점으로 활용할 수 있는 능력을 알고 있습니다.
물론, 여러 기술을 채택하는 것은 오버헤드 없이 이루어지지 않습니다. 어떤 조직에서는 언어 선택에 제한을 가하기도 합니다.
예를 들어, Netflix와 Twitter에서는 시스템의 안정성과 성능을 잘 알고 있기 때문에, 대부분 JVM(Java Virtual Machine)을 플랫폼으로 사용합니다.
또한, 그들은 대규모 운영을 더 쉽게 하는 JVM을 위한 라이브러리와 도구들을 개발하여 사용하고 있습니다. 그러나 Java 기반이 아닌 서비스나 클라이언트는 더 어려워집니다. Twitter나 Netflix 모두 모든 작업에 하나의 기술 스택만을 사용하는 것은 아닙니다.
다른 기술을 혼합하는 것에 대해 고려하는 또 다른 대위법은 크기입니다. 실제로 2주 안에 마이크로서비스를 다시 작성할 수 있다면, 새로운 기술의 채택에 대한 위험을 완화할 수 있을 것입니다.
이 책에서 볼 수 있듯이, 마이크로서비스에 관련된 많은 것들처럼 올바른 균형을 찾는 것이 전부입니다. Chapter 2에서 진화적인 아키텍처에 초첨을 맞춘 기술을 어떻게 선택하는지를 논의하고, 통합(integration)을 다루는 Chapter 4에서 서비스가 어떻게 과도한 커플링(coupling) 없이 서로 독립적으로 기술을 진화시킬 수 있는지를 배우게 될 것입니다.
Resilience
(회복력? 복원력?)
탄력(resilience) 공학의 핵심 개념은 칸막이(bulkhead)입니다. 시스템의 한 구성 요소가 실패했을 경우, 그 장애가 종속되어 있지 않으면 그 문제를 격리할 수 있습니다. 그리고 시스템의 나머지는 계속 동작할 수 있습니다. 서비스의 경계는 명확한 칸막이가 됩니다. 모놀리틱(monolithic) 서비스에서는 서비스가 실패하면 모든 동작이 멈춥니다. 모놀리틱 시스템에서는 장애 가능성을 줄이기 위해 여러 시스템에서 실행할 수 있습니다. 그러나 마이크로서비스에서는 서비스의 전체 장애를 처리하고, 기능성을 적절히 떨어뜨리는 시스템을 구축할 수 있습니다.
그러나 조심해야할 필요가 있습니다. 마이크로서비스가 이러한 향상된 복원력을 적절하게 채택할 수 있도록 하기 위해서는 분산 시스템에서 다루어야 하는 새로운 장애 요인에 대해 이해할 필요가 있습니다. 머신처럼 네트워크에서 실패할 수 있습니다. 이것을 어떻게 다루는지를 알아야 합니다. 그리고 그 장애가 소프트웨어의 최종 사용자에게 어떤 영향을 주는지도 알아야 합니다.
Chapter 11에서 복원력을 더 잘 다루고, 실패 모드를 처리하는 방법에 대해서 이야기할 것입니다.
Scaling
(확장)
대규모의 모놀리틱(monolithic) 서비스에서 우리는 모든 것을 함께 확장해야 합니다.
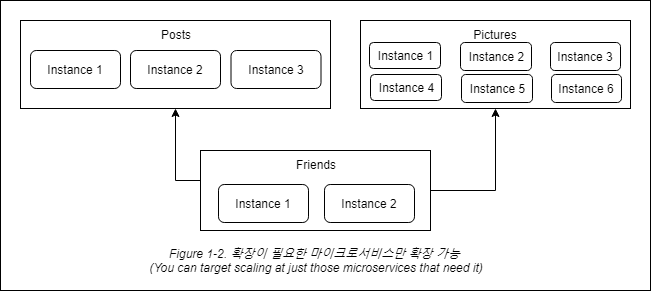
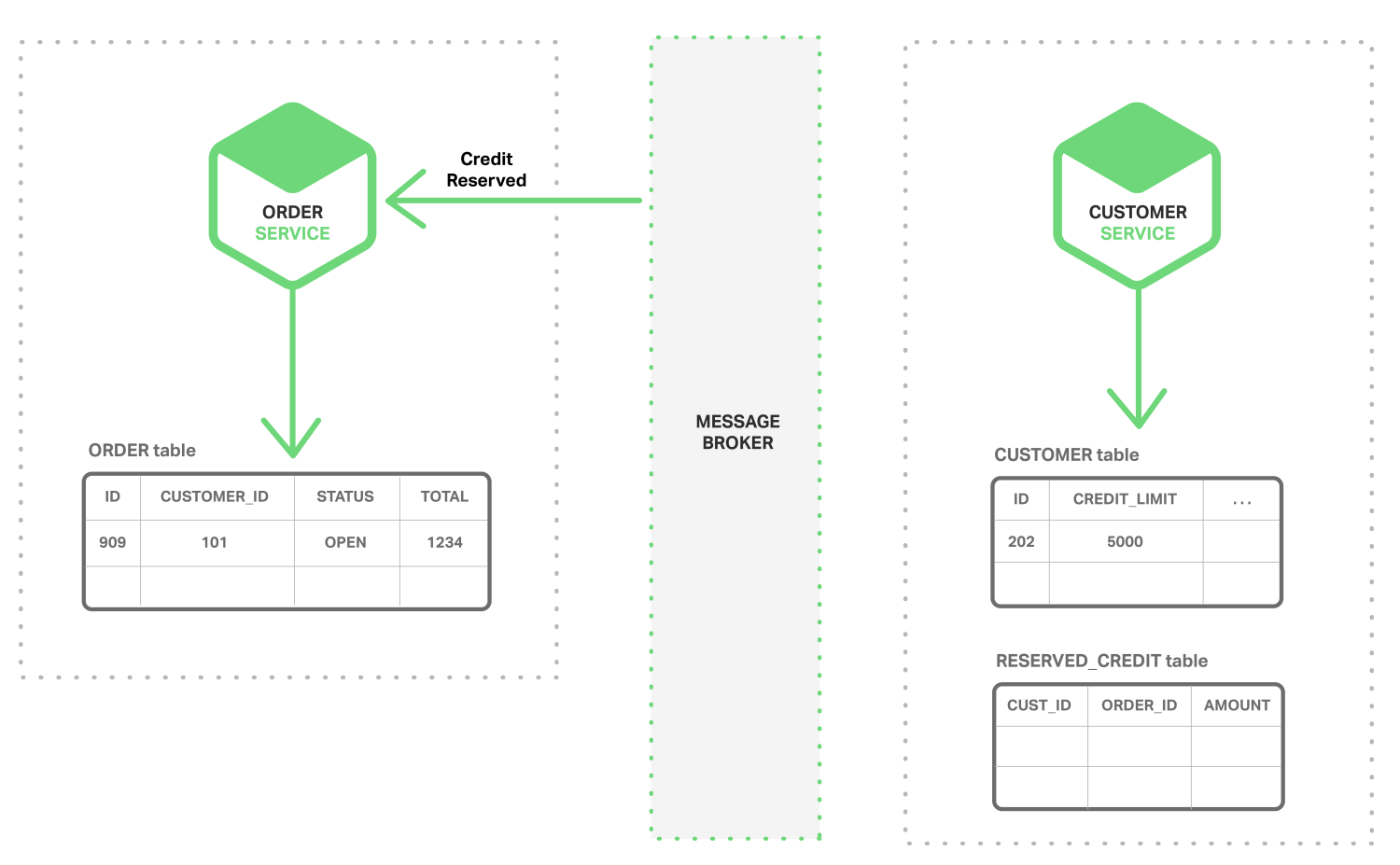
시스템 전체 중 하나의 작은 부분은 성능에 제약이 있지만, 그러한 동작이 하나의 거대한 모놀리틱 어플리케이션에 고정되어 있다면 모든 것을 하나의 조각으로 확장하도록 처리해야 합니다. 더 작은 서비스들은 확장이 필요한 서비스만 확장할 수 있기 때문에, 그림 1-2처럼 더 작고 덜 강력한 하드웨어에서 시스템의 다른 부분들을 실행하도록 할 수 있습니다.
온라인 패션 소매업체인 Glit은 이러한 정확한 이유로 마이크로서비스를 채택했습니다. 2007년에 모놀리틱 Rails 어플리케이션으로 시작해서, 2009년에 Glit의 시스템은 부하에 대처할 수 없었습니다. 시스템의 핵심 부분을 분리함으로써 Glit은 트래픽 급증을 더 잘 처리할 수 있었고, 오늘날 450개가 넘는 마이크로서비스가 있습니다. 각각의 서비스는 여러 개의 분리된 머신에서 실행되고 있습니다.
아마존 웹 서비스(Amazon Web Services)에서 제공하는 것과 같은 주문형(on-demand) 프로비저닝 시스템을 채택할 때, 필요한 부분에 대한 요구에 대해 확장을 적용할 수 있습니다. 이를 통해 비용을 보다 효과적으로 제어할 수 있습니다. 하지만 종종 아키텍처적인 접근 방법이 항상 즉각적인 비용 절감과 밀접한 연관이 있는 것은 아닙니다.
Ease of Deployment
(쉬운 배포)
한 줄을 백만 라인의 모놀리틱 어플리케이션으로 변경하는 것은 변경 사항을 릴리즈(release)하기 위해서 전체 어플리케이션을 배포해야 합니다. 그것은 커다란 영향을 미치는, 고위험의 배포일 수 있습니다. 실제로, 큰 영향을 미치고 고 위험을 가지는 배포는 이해할 수 없는 공포로 인해 드물게 발생합니다. 불행하게도, 이것은 우리의 변경 사항들이 우리의 새로운 버전의 어플리케이션이 다수의 변경 사항을 가진 제품화가 될 때까지 릴리즈 사이에 쌓이면서 점점 커지는 것을 의미합니다. 릴리즈 사이에 델타(변경사항)가 더 클수록 무엇인가가 잘못된 위험이 더 높아집니다!
마이크로서비스에서는 단일 서비스를 변경할 수 있습니다. 그리고 나머지 시스템에 독립적으로 배포할 수 있습니다. 이를 통해 코드를 더 빠르게 배포할 수 있습니다. 만약 문제가 발생하면, 개별 서비스로 신속하게 격리될 수 있고, 빠른 롤백을 쉽게 달성할 수 있습니다. 그것은 고객에게 더 빠르게 새로운 기능을 제공할 수 있음을 의미합니다. Amazon과 Netflix같은 조직들이 왜 이러한 아키텍처를 사용하는지의 주된 이유 중 하나입니다. 마이크로서비스는 가능한 많은 방해물을 제거하여 소프트웨어가 밖으로 나갈 수 있게 합니다. 이 공간에서의 기술은 지난 2년 동안 크게 변화했습니다. 그리고 Chapter 6에서 마이크로서비스 세계에서 배포에 관한 주제를 더 깊게 살펴볼 것입니다.
Organizational Alignment
(조직적 조정)
우리중 많은 사람들이 대규모 팀과 코드베이스와 관련된 문제들을 경험했습니다. 이 문제는 팀이 분산될 때 더 심해질 수 있습니다. 우리는 또한 더 작은 코드베이스에서 작업하는 더 작은 팀이 더 생산성이 높은 경향이 있다는 것을 알고 있습니다.
마이크로서비스는 아키텍처를 조직에 더 잘 연계할 수 있게 합니다. 그리고, 하나의 코드베이스에서 작업하는 사람의 수를 최소화하여 팀의 크기와 생산성 측면에서 최고의 결과를 얻을 수 있게 합니다. 우리는 팀 간의 서비스 소유권을 옮겨서 하나의 서비스에 대해 일하는 사람들을 같은 곳에 있도록 할 수 있습니다. Chapter 10에서 Conway의 법칙을 논의할 때 이 주제에 대해서 훨씬 더 자세히 설명할 것입니다.
Composability
(결합성)
분산 시스템과 SOA에서의 주요 약속 중 하나는 기능을 재사용하는 기회를 열어놓는 것입니다. 마이크로서비스에서는 기능을 다른 목적에 대해서 다양한 방법으로 사용하게 합니다. 소비자가 우리 소프트웨어를 어떻게 사용하는지에 대해 생각할 때 특히 중요할 수 있습니다. 데스크톱 웹 사이트나 모바일 어플리케이션에 대해서 좁혀서 생각할 때, 시간은 흘러갑니다. 이제 우리는 웹, 네이티브 어플리케이션(스마트폰 등에 직접 설치해야 하는 어플리케이션), 모바일 웹, 티블릿 앱, 혹은 웨어러블 디바이스에 대해 서로 결합을 짜내기 위한 무수한 방법을 생각할 필요가 있습니다.
조직이 좁은 채널 측면에서 생각이 고객 참여의 전체론적인 개념으로 옮겨감에 따라 계속되게 할 수 있는 아키텍처가 필요합니다.
마이크로서비스로 외부 당사자가 처리할 수 있도록 우리 시스템의 경계선들을 오픈하는 것에 대해 생각해 보십시오. 상황이 바뀜에 따라 우리는 다른 방식으로 물건들을 만들 수 있습니다. 모놀리틱 어플리케이션에서는 밖에서 사용할 수 있는 하나의 거칠게 나누어진 경계가 있는 경우가 많습니다. 더 유용한 것을 얻기 위해 그것을 깨고 싶다면, 해머가 필요할 것입니다! Chapter 5에서 기존의 모놀리틱 시스템을 분해하고, 재사용 가능하게 바꾸고, 마이크로서비스로 재구성할 수 있는 방법에 대해서 논의할 것입니다.
Optimizing for Replaceability
(대체 가능성의 최적화)
만약 여러분이 중간 규모 이상의 조직에서 일하고 있다면, 구석에 있는 크고 끔직한 레거시 시스템에 대해서 알고 있을 가능성이 있습니다. 누구도 만지고 싶지 않은 것. 여러분의 회시가 어떻게 운영되는지에 대해서 필수적인 어떤 것이지만, 이상한Fortran(포트란) 변수로 작성되어 있고, 25년전에 끝난 하드웨어에서만 실행됩니다. 왜 대체되지 않았을까요? 당신은 이유를 알고 있습니다. : 너무 크고 위험한 일이기 때문입니다.
개별 서비스가 작으면, 다 나은 구현으로 대체하거나 심지어 전부 지우는데 들어가는 비용을 관리하는 것이 훨씬 더 쉽습니다. 하루에 얼마나 자주 너무 걱정하지 않고 100줄 이상의 코드를 지우고 있습니까? 크기가 유사한 마이크로서비스가 종종 있기 때문에, 서비스를 완전히 재작성하거나 삭제하기 위한 장벽은 매우 낮습니다.
마이크로서비스 접근 방법을 사용하는 팀들은 필요할 때 서비스를 완전히 다시 작성하고, 더 이상 필요 없을 때 서비스를 죽이는데 익숙합니다 코드베이스가 수 백줄에 불과하면, 사람들이 감정적으로 애착을 갖기 어렵습니다. 그리고 대체하는 비용이 매우 적습니다.
What About Service-Oriented Architecture?
SOA(Service-Oriented Architecture)는 여러 서비스가 일부 기능 집합을 제공하기 위해 협력하는 설계 접근 방법입니다. 여기서 서비스는 일반적으로 완전히 분리된 운영 체제 프로세스를 의미합니다. 이러한 서비스들 사이의 통신은 프로세스 경계 내에서의 메소드 호출보다는 네트워크 호출을 통해 이루어집니다. SOA는 대규모의 모닐리틱 어플리케이션의 문제점을 해결하기 위한 접근 방법으로 등장했습니다.
SOA는 소프트웨어의 재사용성을 촉진하기 위한 목적으로 하는 접근 방식입니다. 예를 들면, 두개 이상의 최종 사용자 어플리케이션은 모두 동일한 서비스를 사용할 수 있습니다. 서비스의 의미가 너무 많이 변하지 않는 한, 이론적으로 아무도 모르게 하나의 서비스를 다른 서비스로 대체하는 것이 가능하기 때문에 소프트웨어를 유지하거나 재작성하는 것이 더 쉽습니다.
SOA는 매우 현명한 아이디어입니다. 그러나, 많은 노력에도 불구하고, SOA를 잘 수행하는 방법에 대한 좋은 합의가 부족합니다. 개인적인 견해로는 산업계의 상당수는 문제에 대해 충분히 전체적인 관점에서 들여다보지 못했고, 이 영역에서 다양한 벤더들이 내놓은 이야기들에 대한 강력한 대안을 정하지 못했습니다.
SOA의 문앞에 놓인 많은 문제들은 통신 프로토콜(예를 들면, SOAP), 벤더들의 미들웨어, 서비스 세분화에 대한 가이드 부족, 혹은 시스템을 분할하는 장소 선택에 대한 잘못된 가이드와 같은 실제적인 문제들이었습니다. 우리는 책의 나머지 부분에서 각각에 대해서 다룰 것입니다. 냉소적인 사람은 벤더들이 SOA 운동을 더 많은 제품들을 팔기 위한 방법으로 선임(어떤 경우에는 주도)했음을 암시할지도 모릅니다. 그리고 그러한 똑같은 제품들은 종국에 SOA의 목표를 훼손시켰습니다.
SOA에 대한 기존 지혜의 대부분은 큰 어떤 것을 작게 나누는 방법을 이해하는데 도움이 되지 않습니다. SOA는 얼마나 큰 것이 너무 큰 것인가를 이야기하는 것이 아닙니다. SOA는 실제 세상에서, 서비스가 과도하게 결합되지 않도록 하는 실질적인 방법에 대해서 충분히 이야기하지 않습니다. 언급되지 않은 것들의 수는 대부분 SOA와 연관된 위험이 발생한 곳입니다.
마이크로서비스 접근 방법은 SOA를 더 잘 수행할 수 있는 시스템과 아키텍처에 대한 더 나은 이해를 바탕으로 실제 세상에서 사용함으로 드러났습니다. 따라서 XP나 Scrum이 Agile 소프트웨어 개발에 대한 특정 접근법인 것과 같은 방식으로 마이크로서비스가 SOA에 대한 특정한 접근방법으로 생각해야 합니다.
Other Decomposition Techniques
(기타 분해 기법)
여러분이 그것에 관심을 기울이기 시작할 때, 마이크로서비스 기반 아키텍처의 많은 유익한 점들은 어떻게 문제를 해결하는지 더 많은 선택의 경우를 준다는 granular nature(낱개 특성)과 사실로부터 나옵니다. 하지만, 유사한 분해 기법으로 동일한 유익을 얻을 수 있을까요?
Shared Libraries
(공유 라이브러리)
사실상 모든 언어에 내장된 매우 표준적인 분해 기법은 여러 라이브러리로 코드베이스를 분해하는 것입니다. 이러한 라이브러리들은 3rd party가 제공하거나 조직 내에서 만들 수 있습니다. 라이브러리들은 팀과 서비스들 간에 기능을 공유할 수 있는 방법을 제공합니다. 예를 들어, 제가 유용한 콜렉션 유틸리티 집합을 만들거나 재사용할 수 있는 통계 라이브러리를 만들 수 있습니다.
팀은 이러한 라이브러리들을 기준으로 조직할 수 있고, 라이브러리들은 재사용 할 수 있습니다. 하지만, 몇 가지 단점이 있습니다.
첫번째로 진정한 기술 이질성을 잃어버립니다. 라이브러리는 전형적으로 동일한 언어로 되어 있어야 하거나, 최소한 동일한 플랫폼에서 실행되어야 합니다. 두번째, 시스템의 일부를 서로 독립적으로 확장하는 용이성이 감소합니다. 다음으로는 동적으로 링크된 라이브러리를 사용하지 않으면, 전체 프로세스를 재배포하지 않고서 새로운 라이브러리를 배포할 수 없으므로, 변경 사항을 독립적으로 배포할 수 있는 능력이 줄어듭니다. 그리고 아마도 시스템의 탄력성을 보장하기 위해 구조적인 안전 조치들을 세우기 위한 분명한 솔기가 부족할 수도 있습니다.
공유 라이브러리들은 그들만의 장소를 가지고 있습니다. 조직 전체에서 재사용하고 싶어서 비즈니스 도메인에 특정되지 않는 일반적인 작업에 대한 코드를 스스로 만든다면, 재사용 가능한 라이브러리에 대한 분명한 후보자가 될 수 있습니다. 비록 그렇다고 할지라도, 여러분은 충분히 주의해야 합니다. 서비스간 통신에 사용되는 공유 코드는 Chapter 4에서 논의할 예정인, 연결되는 지점(point of coupling)이 될 수 있습니다.
서비스들은 공통 코드를 재사용하기 위해 3rd party의 라이브러리들을 매우 많이 사용할 수 있고, 그렇게 해야만 할 것입니다. 하지만, 그것들은 우리를 거기에 데려다 주지 않습니다.
Modules
(모듈)
어떤 언어들은 간단한 라이브러리들을 넘어서는 자체의 모듈식 분해 기법을 제공합니다. 실행 프로세스에 모듈을 배포할 수 있도록 모듈의 라이프사이클 관리를 허용하기 때문에 전체 프로세스를 다운시키지 않고 변경 작업을 수행할 수 있습니다. OSGI(Open Source Gateway Initiative)는 하나의 기술 특화된 모듈식 분해 접근 방식을 요구합니다.
Java 자체는 모듈에 대한 진정한 개념을 가지고 있지 않습니다. 따라서 Java 9가 언어에 추가된 것을 보여줄 때까지 적어도 기다려야만 합니다.
OSGI는 Eclipse Java IDE에 플러그인을 설치하기 위한 프레임워크로 나타났습니다. 지금은 라이브러리를 통해 자바에 모듈 개념을 새로 장착하는 방법으로 사용되고 있습니다. OSGI의 문제는 언어 자체에서 충분한 지원 없이는 모듈 라이프사이클 관리와 같은 것을 억지로 실행하려고 하는 것입니다. 이러한 결과로 적절한 모듈 분리를 제공하기 위해서 모듈 작성자가 더 많은 일을 해야 합니다. 프로세스 경계 내에서 모듈이 서로 지나치게 결합하는 것은 모든 종류의 문제를 야기하는 함정에 훨씬 더 쉽게 빠집니다. OSGI에 대한 경험에서 산업계 내 동료들과 어울릴 때, 아무리 좋은 팀이라도 OSGI가 보장하는 이익보다 훨씬 더 큰 복잡성의 원인이 되기 쉽다는 것입니다.
Erlang은 모듈이 언어 런타임 내에 구워지는 다른 접근 방법을 따릅니다. 이처럼 Erlang은 모듈식 분해에 대해 매우 성숙한 접근 법입니다. Erlang 모듈은 문제없이 중단, 재시작, 업그레이드 될 수 있습니다. Erlang은 주어진 시간 대에 두개 이상의 모듈 버전이 실행되는 것을 지원합니다. 따라서 더 우아한 모듈 업그레이드가 가능합니다.
Erlang 모듈의 능력은 실제로 인상적이지만, 이러한 기능을 갖춘 플랫폼을 사용할 만큼 충분히 운이 좋을지라도, 일반적인 공유 라이브러리와 마찬가지로 동일한 단점이 있습니다.
우리는 새로운 기술들을 사용하는 능력이 엄격히 제안되어 있으며, 독립적으로 확장할 수 있는 방법에 대해서도 제한적이고, 지나치게 커플된(coupled) 통합 기술 (integration techniques) 쪽으로 표류할 수 있고, 구조적인 안전 조치를 위한 이음새가 부족합니다.
공유할 만한 가치가 있는 마지막 관찰이 하나 있습니다. 단일 모놀리틱 프로세스 내에 기술적으로, 잘 정리된, 독립적인 모듈을 만드는 것이 가능해야 합니다. 하지만, 거의 이러한 일은 일어나지 않습니다. 모듈은 그 자체로 나머지 코드들과 밀접하게 결합하여 주요 장점 중 하나를 버립니다. 프로세스 경계를 분리하는 것은 이 점에 있어서 청결한 위생을 실행합니다. (혹은 최소한 잘못된 것을 더 하기 어렵게 합니다!)
물론, 이것이 프로세스 분리의 주요 요인이라고 제안하지는 않겠지만, 프로세스 경계 내에서 모듈 분리의 약속이 현실 세계에서는 거의 제공되지 않는 다는 점이 흥미롭습니다.
따라서, 프로세스 경계 내에서 모듈식 분리는 시스템을 서비스로 분해하는 것 뿐만 아니라 행하고자 하는 어떤 것일 수도 있지만, 그 자체로 모든 것을 해결하는데 도움이 되는 것은 아닙니다. 만약 순수한 Erlang Shop이라면 Erlang의 모듈 구현 품질은 당신에게 매우 먼 길을 가져다 줄 수 있습니다. 하지만, 여러분 중의 많은 사람들이 그 상황에 있지는 않을 거라고 생각합니다. 우리에게 남은 것은, 모듈이 공유 라이브러리와 동이한 유익을 가져다 주는 것으로 보아야 한다는 것입니다.
No Silver Bullet
(은 총알은 없다)
끝내기 전에, 마이크로서비스는 무료 점심이나 은 총알이 아니고, 황금 망치처럼 나쁜 선택을 해야 한다는 것을 말하고 싶습니다. 마이크로서비스는 분산 시스템과 관련된 모든 복잡성을 가지고 있습니다. 그리고 비록 우리가 분산 시스템을 어떻게 잘 관리하는지에 대해 많이 배운다고 할지라도 (이 책에서 다룰 것입니다.) 여전히 어렵습니다. 만약 여러분이 모놀리틱 시스템 관점에서 출발한다면, 배포, 테스트, 모니터링을 훨씬 더 잘 처리하여 지금까지 우리가 살펴본 장점들을 풀어서 활용해야 합니다. 또한,시스템을 어떻게 확장하는지, 복원력이 있는지 어떻게 확인하는지에 대해 다르게 생각할 필요가 있습니다. 분산 트랜잭션이나 CAP 이론이 두통을 선사해도 놀라지 마십시오.
모든 회사, 조직, 시스템은 다릅니다. 마이크로서비스가 여러분에게 적합한지 아닌지, 마이크로서비스를 얼마나 적극적으로 채택할 수 있는지에 여러 가지 요소들이 작용할 것입니다. 이 책의 각 장들을 통해서 꾸준한 경로를 계획하는데 도움이 되는 잠재적 함정을 강조하는 가이드를 제공하려고 노력할 것입니다.
Summary
바라건데, 이제부터 여러분은 마이크로서비스가 무엇인지, 다른 구성 기술들과 다른 점이 무엇인지, 주요 장점 중 일부가 무엇인지 알고 있습니다. 다음 각 장에서는 어떻게 이러한 장점들을 달성하는지, 일반적인 함정을 어떻게 피하는지에 대해서 더 자세히 다룰 것입니다.
다루어야 할 많은 주제들이 있지만, 어딘가에서부터 시작해야 합니다. 마이크로서비스가 소개하는 주요 과제 중 하나는 우리 시스템의 진화를 가이드하는 사람들 : 아키텍트들의 역할에 변화가 있다는 것입니다. 다음에 우리는 이 새로운 아키텍처를 최대한 활용할 수 있도록 이 역할에 대한 몇 가지 다른 접근 방법을 살펴볼 것입니다.


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/814