Key Concepts of Deep Neural Networks
(Deep Neural Network의 핵심 개념)
Deep-Learning Network는 흔히 있는 단일 은닉 레이어(single hidden layer)와는 깊이에서 구별된다. 즉, 패턴 인식의 여러 과정에서 데이터가 통과하는 노드 레이어의 숫자에서 구별된다.
전통적인 머신러닝에서는 하나의 입력과 하나의 출력, 그 사이의 최소한 하나의 숨겨진 레이어로 이루어진 얕은 그물망을 사용한다. 3개 이상의 레이어(입력과 출력을 포함하여)는 "Deep" Learning의 자격을 갖는다.따라서, deep은 하나 이상의 숨겨진 레이어를 의미하는 엄격하게 정의된 기술적인 용어이다.
Deep-Learning 네트워크에서, 노드의 각 레이어는 이전 레이어의 출력값을 근거로 고유한 일련의 특징을 학습한다. 신경망(neural net)으로 진화할수록 노드에서는 더 복잡한 특징들을 인식할 수 있고, 앞의 레이어로부터 특징들을 취합하여 재조합할 수 있다.
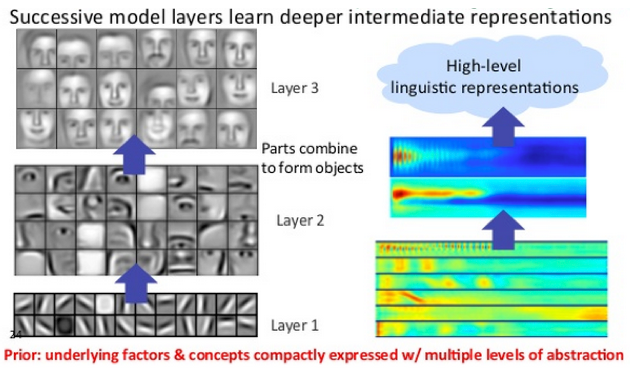
이것은 복잡도와 추상성이 증가하는 계층 구조인 Feature Hierarchy(특징 계층)이라고 알려져 있다. 이것을 통해 deep-learning network는 비선형 함수를 통과하는 수십억개의 파라미터를 가진 매우 크고, 고차원의 데이터들을 처리할 수 있다.
무엇보다도, 이러한 그물망은 세상에 압도적으로 존재하는 라벨이 붙여지지 않고, 구조화되어 있지 않은 데이터내에 잠재되어 있는 구조를 발견할 수 있다. 구조화되어 있지 않은 데이터는 다른 말로 하면, 사진, 텍스트, 비디오, 오디오와 같은 원시 미디어이다. 그러므로, deep learning으로 가장 잘 해결할 수 있는 문제점 중 하나는 세상에 있는 원시 미디어, 라벨이 붙여져 있지 않은 미디어를 처리하고 클러스터링하여, 관계형 데이터베이스 내에 있는 사람이 구성하지 않은 데이터에 대한 유사성과 이상을 식별하거나 이름을 붙이는 것이다.
예를 들어, deep learning은 수백만 개의 이미지를 가지고 한 귀퉁이의 고양이, 다른 모퉁이의 고양이, 모든 할머니 사진들 중에 3분의 1 정도의 유사성에 따라 클러스터를 구성할 수 있다. 이것은 소위 스마트 포토 앨범의 기반이 된다.
이제 같은 아이디어를 다른 데이터 타입에 적용해 보자. Deep learning은 이메일이나 뉴스 기사와 같은 원시 텍스트를 클러스터링할 수 있다. (cluser:조밀하게 모아서 무리 짓는 것) 벡터 공간의 한쪽 귀퉁이에 짜증내는 불평으로 가득찬 이메을을 모아놓고, 다른 편에는 만족하는 고객들 혹은 스팸봇이 보낸 메시지들을 모아놓을 수 있다. 이것은 다양한 메시지 필터의 기본이다. 그리고 CRM(Customer Relationship Management)에서 사용될 수 있다. 음성 메시지에도 동일하게 적용된다. 시간에 따라서 데이터는 정상적이고 건강한 행동과 비정상적이고 위험한 행동 중심으로 데이터를 모을 수 있다. 시간에 따른 데이터가 스마트폰에서 생성된다면, 사용자의 건강과 습관에 대한 insight(통찰)를 제공해 줄 것이다. 데이터가 자동차부품(autopart)에서 생성된다면, 치명적인 고장을 예방하는데 사용될 수 있다.
Deep-learning network는 대부분의 전통적인 머신러닝 알고리즘과는 다르게 사람의 개입없이 자동으로 특징을 추출한다. 주어진 특징 추출은 데이터 사이언티스트들이 수년에 걸쳐 이루어낼 수 있는 작업이므로, deep learning은 전문가 수가 제한되어 있다는 애로 사항을 회피할 수 있는 방법이다. 근본적으로 확장하지 않고도, 규모가 작은 데이터 사이언스 팀의 능력을 보강할 수 있다.
라벨이 붙여지지 않은 데이터로 학습하는 경우, deep network내의 각 노드 레이어는 샘플에서 뽑아낸 입력 데이터를 반복적으로 재구성하도록 시도하고, 네트워크의 추측과 입력 데이터 자체의 확률 분포 사이의 차이를 최소화하려고 함으로써 자동으로 특징을 학습한다. 예를 들면, 제한된 볼츠만 머신(Boltzmann Machine)은 이러한 방식으로 소위 재구성 데이터를 생성한다.
이 과정에서, 이러한 네트워크는 어떤 관련있는 특징들과 최적의 결과 사이에 상관관계를 인식하는 학습을 한다. 네트워크는 전체적으로 재구성되었든지, 라벨이 붙여진 데이터든지 상관없이, 특징을 가진 신호와 그런 특징들이 설명하는 것 사이를 연결한다.
라벨이 붙여진 데이터(분류된 데이터)로 학습한 Deep-learning network는 비정형 데이터에도 적용될 수 있기 때문에 머신러닝 보다 훨씬 더 많은 입력 데이터에 접근할 수 있다. 고성능을 위한 방법이다. 더 많은 데이터를 학습할수록, 더 정확해질 것이다. (많은 데이터로 학습한 적합하지 않은 알고리즘은 적은 데이터로 학습한 훌륭한 알로리즘보다 더 나은 결과를 낼 수 있다.) 라벨이 붙어 있지 않은 막대한 양의 데이터를 처리하고 학습한 deep-learning의 능력은 이전 알고리즘에 비해 차별화된 이점을 제공한다.
Deep-learning network는 출력 레이어에서 종료된다 : 특정 결과나 라벨에 가능성을 지정하는 기호(logistic), softmax(??), 분류사(classifier:어떤 의미 그룹에 속하는지를 보여주는 접사나 단어) 우리는 이것을 예측적이다라고 하지만, 포괄적인 의미에서의 예측을 의미한다. 예를 들어, 이미지형태로 원시 데이터가 주어진다면, deep-learning network는 입력데이터가 90%로 사람을 나타낸다고 결정할 수 있다.


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/789