IPC Technologies
선택할 수 있는 많은 서로 다른 IPC 기술들이 있다. 서비스가 HTTP기반 REST나 Thrift와 같은 동기식 request/response기반 통신 메커니즘을 사용하할 수 있다. 그렇지 않으면, 비동기식인 AMQP나 STOMP와 같은 메시지 기반 통신 메커니즘을 사용할 수도 있다. 또한 다양한 서로 다른 메시지 구성 방식이 있다. 서비스들은 JSON이나 XML과 같은, 사람이 읽을 수 있는 텍스트 기반 구성 방식을 사용할 수도 있다. 그렇지 않으면, Avro나 Protocol Buffer와 같은 바이너리 구성 방식(더 효율적이다)을 사용할 수도 있다. 동기식 IPC 메커니즘은 나중에 살펴보고, 먼저 비동기식 IPC 메커니즘에 대해서 논의해 보자.
Asynchronous, Message-Based Communication
(비동기적인, 메시지 기반 통신)
메시지를 사용할 때, 프로세스들은 비동기적으로 메시지를 교환하면서 통신한다.
클라이언트는 메시지를 서비스에 보내서 요청한다. 만약 서비스가 응답을 보내야 한다면, 클라이언트에 다른 메시지로 응답을 보낸다. 통신은 비동기로 이루어지기 때문에, 클라이언트는 응답을 기다리며 대기하지 않는다. 대신, 클라이언트는 즉시 응답을 받지 않는다는 가정하에 구현된다.
메시지는 header(sender-송신자와 같은 메타데이터)와 message body로 이루어져 있다. 메시지는 channel을 통해 교환된다. Producer의 숫자에 상관없이 channel을 통해서 메시지를 보낼 수 있다. 유사하게, Consumer의 숫자에 상관없이 channel로부터 메시지를 받을 수 있다. Point-to-Point, Publish-Subscribe의 2가지 channel 종류가 있다.
- Point-to-Point channel : Channel에서 데이터를 읽는 정확하게 하나의 Consumer에게 메시지를 전송한다. 앞서 설명한 One-to-One 상호작용 형태의 경우에 Service는 Point-to-Point channel을 사용한다.
- Publish-Subscribe channel : Channel에 추가된 모든 consumer에 메시지를 전송한다. 위에서 설명한 One-to-Many 상호작용 형태의 경우에 Service는 Publish-Subscribe channel을 사용한다.
다음 다이어그램은 택시 호출 어플리케이션이 어떻게 Publish-Subscribe Channel을 사용하는지를 보여준다.
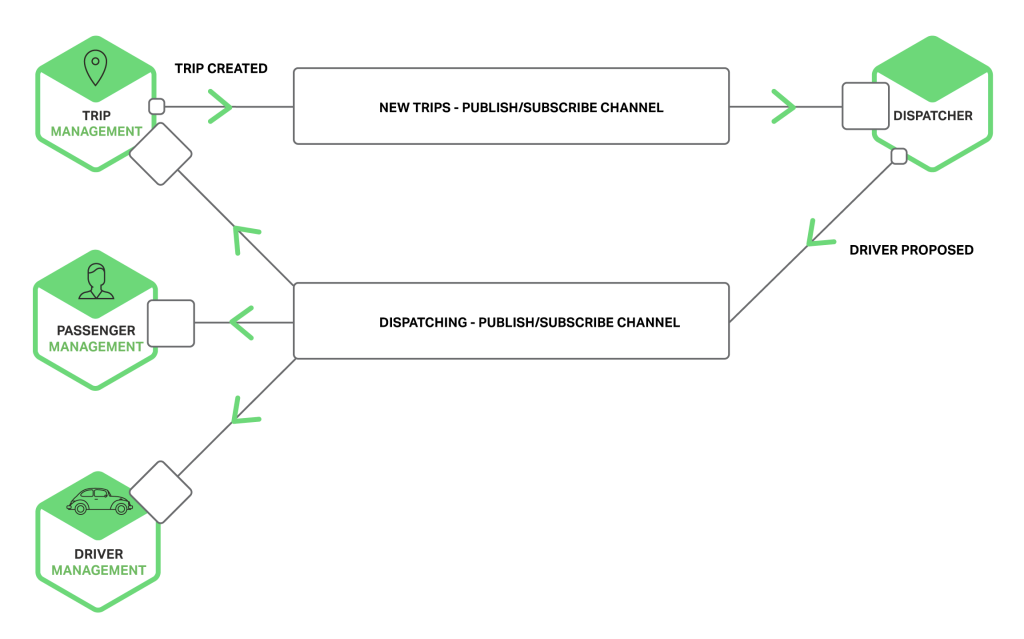
Trip Management Service(이동 관리 서비스)는 Trip message를 생성하여 Publish-Subscribe Channel에 적어서 Dispatcher와 같은 연관된 서비스에 알려 준다. Dispatcher는 가용 가능한 운전자를 찾아서 Publish-Subscribe Channel을 통해 운전자에게 제안하는 메시지를 적어서 다른 서비스들에 알려 준다.
선택할 수 있는 메시지 시스템들은 많이 있다. 다양한 프로그래밍 언어를 지원하는 것을 골라야 한다. 어떤 메시지 시스템들은 AMQP와 STOMP와 같은 표준 프로토콜을 지원한다. 다른 메시지 시스템들은 소유권을 주장할 수 있지만 문서화된 프로토콜을 가지고 있다. RabbitMQ, Apache Kafka, Apache ActiveMQ, NSQ를 포함하여 선택할 수 있는 많은 오픈소스 메시지 시스템들이 있다. 그 시스템들은 모두 높은 수준으로 메시지와 채널을 지원한다. 신뢰성, 고성능, 확장성을 위해서 모두 노력하고 있다. 그러나, 각각의 broker의 상세 메시지 모델에 있어서는 중요한 차이점이 있다.
메시지를 사용하는 것에는 많은 장점이 있다.
- Decouples the client from the service(서비스와 클라이언트의 분리) : 클라이언트는 적합한 채널에 메시지를 보냄으로 간단하게 요청한다. 클라이언트는 서비스 인스턴스를 정확하게 알지 못한다. 서비스 인스턴스의 위치를 알아내기 위해서 Discovery mechanism(발견 메커니즘)을 사용할 필요도 없다.
- Message Buffering(메시지 버퍼링) : HTTP와 같은 동기식 request/response 프로토콜에서는 클라이언트와 서비스 모두 메시지 교환 내내 이용 가능해야 한다. 반대로, 메시지 브로커는 Consumer에 의해 처리될 수 있을 때까지 채널에 쓰여진 메시지를 큐에 저장한다. 예를 들면, 이것은 온라인 스토어가 주문 처리 시스템이 느리거나 이용할 수 없을 때라도 고객으로부터 주문을 받을 수 있다는 것을 의미한다. 주문 메시지는 단순히 큐에 저장되어 있다.
- Flexible client-service interactions(유연한 클라이언트-서버 상호작용) : 메시지는 앞에서 설명한 모든 형태의 상호작용을 지원한다.
- Explicit inter-process communication(분명한 IPC 통신) : RPC기반 메커니즘은 원격 서비스를 로컬 서비스를 호출하는 것과 동일하게 보고 호출하려고 한다. 그러나, 물리적이고 부분적으로 실패할 수 있는 가능성 때문에 실제로는 상당히 다르다. 메시지는 이러한 차이점들을 매우 분명하게 하여 개발자들을 달래서 안심시키지 않는다. (개발자들이 명시적으로 부분적인 실패를 감안하여 안정성 있는 프로그램을 작성한다는 의미.)
하지만, 메시지를 사용하는 것은 다음과 같은 불리한 점이 있다.
- Additional operational complexity(추가적인 운영 복잡성) : 메시지 시스템은 그러나 또다른 시스템 컴포넌트로 설치, 설정, 운영 되어야 한다. 메시지 브로커는 필수적으로 고가용성을 가져야 한다. 그렇지 않으면 시스템의 신뢰성에 영향을 받는다.
- Complexity of implementing request/response-based interaction(요청/응답 기반 상호 작용 구현 복잡성) : Request/Response(요청/응답) 형태의 상호작용은 약간의 구현이 필요하다. 각각의 요청 메시지는 응답 채널 식별자와 상관관계 식별자를 포함해야만 한다. 서비스는 응답 채널에 상관관계 ID를 포함한 응답 메시지를 작성해야 한다. 클라이언트는 요청에 대한 응답을 매치시키기 위해 상관관계 ID를 사용한다. 종종 메시지보다 직접적으로 요청/응답을 지원하는 IPC 메커니즘을 사용하는 것이 더 쉽다.
메시지 기반 IPC를 사용하는 것에 대해 알아보았는데, 이제 요청/응답 기반 IPC에 대해서 검토해 보자.
Synchronous, Request/Response IPC
동기식 Request/Response 기반 IPC 메커니즘을 사용할 때, 클라이언트는 서비스에 요청을 보낸다. 서비스는 요청을 처리하고, 응답을 돌려 보낸다. 많은 클라이언트에서 요청을 보낸 thread들은 응답을 기다리는 동안 대기한다. 비동기식 Event-Driven 클라이언트 코드를 사용한 다른 클라이언트들은 Futures나 Rx Observables로 캡슐화되어 있다. (캡슐화 : 자세한 내부 구현을 드러내지 않고 어떤 기능을 제공하는지만 공유하는 객체지향 프로그래밍 방식) 그러나 메시지를 사용할 때와는 다르게 클라이언트는 응답이 시기적절하게 도착할 것을 가정한다. 선택할 수 있는 많은 프로토콜들이 있다. 2가지 가장 인기있는 프로토콜은 REST와 Thrift이다. 먼저 REST를 살펴보자.
REST
오늘날, API를 REST 스타일로 개발하는 것이 유행이다. REST는 (거의 대부분) HTTP를 사용하는 IPC 메커니즘이다. REST에서의 주요 개념은 리소스이다. 리소스는 일반적으로 Customer나 Product와 같은 Business Object를 나타내거나 Business Object의 Collection을 나타낸다. REST는 HTTP의 동사를 사용하여 URL로 참조되는 리소스를 다룬다. 예를 들면, GET 요청은 XML 문서나 JSON Object 형태인 리소스의 설명을 리턴한다. POST 요청은 신규 리소스를 생성하고, PUT 요청은 리소스를 업데이트한다. REST의 창시자인 Roy Fielding의 말을 인용하자면,
"REST는 전체적으로 적용하고자 할 때, 구조적인 제한점들이 있고, 컴포넌트 상호작용의 확장성, 인터페이스의 보편성, 컴포넌트 배포의 독립성, 상호 작용의 지연을 줄이기 위한 중개 컴포넌트와 보안성 강화, 레가시 시스템들에 대한 캡슐화를 강조한다."
** Fielding, 아키텍처 스타일과 네트워크 기반 소프트웨어 아키텍처 디자인 (Architectural Styles and the Design of Network-based Software Architecture)
다음 다이어그램은 택시 호출 어플리케이션이 REST를 사용하는 방법 중 한가지를 보여주고 있다.
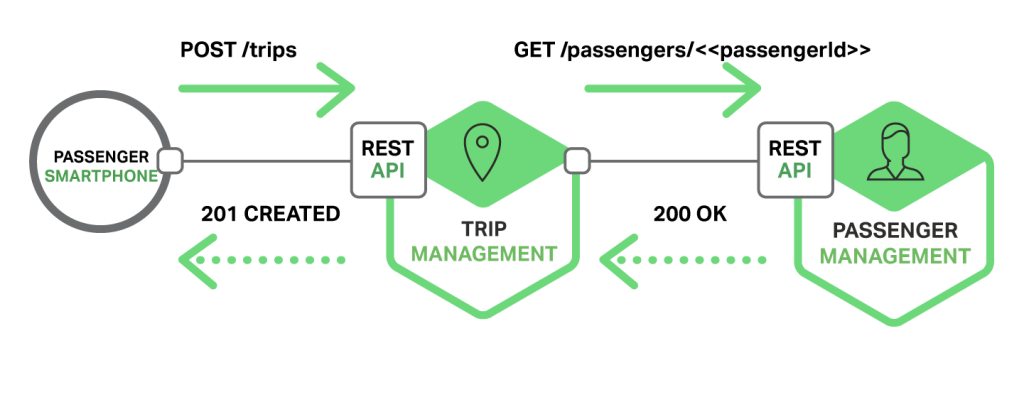
승객의 스마트폰은 Trip Management Service에 /trips 리소스로 POST 요청을 만들어서 보낸다. 이 서비스는 Passenger Management Service에 승객의 정보를 얻기 위해 GET 요청을 보낸다. 승객이 trip을 생성할 수 있는지 인증을 한 다음에 Trip Management Service는 trip을 생성하고 201 응답을 스마트폰에 보낸다.
많은 개발자들이 HTTP기반 RESTful API에 대해서 불만을 제기한다. 그러나 Fielding이 설명한 것처럼, 전부 사실은 아니다. (전혀 관계없는) Leonard Richardson은 다음에 설명된 레벨로 이루어진 매우 유용한 REST 성숙 모델을 정의했다.
- Level 0 : 레벨 0 API를 사용하는 클라이언트는 유일한 URL Endpoint에 HTTP POST 요청으로 서비스를 호출한다. 각각의 요청은 수행할 동작이 정의되어 있고, 동작의 목표(예를 들어, Business Object)와 파라미터들이 정의되어 있다.
- Level 1 : 레벨 1 API는 리소스에 대한 개념을 지원한다. 리소스에 대한 동작을 수행하기 위해 클라이언트는 수행할 동작과 파라미터가 정의되어 있는 POST 요청을 작성한다.
- Level 2 : 레벨 2 API는 동작을 수행하기 위해 HTTP 동사를 사용한다. 조회하기 위해서 GET을, 생성하기 위해 POST를, 업데이트 하기 위해서 PUT을 사용한다. 요청 시, 쿼리 파라미터와 본문으로 동작의 파라미터들을 지정한다. 서비스들은 GET 요청에 대한 캐싱과 같은 웹 인프라를 사용할 수 있다.
- Level 3 : 레벨 3 API 설계는 끔찍하게 이름붙여진 HATEOAS(Hypertext As The Engine Of Application State-응용프로그램 상태 엔진으로서의 Hypertext) 원리를 기반으로 하고 있다. 기본 아이디어는 GET 요청의 리턴된 리소스 표현에 리소스가 수행가능한 링크가 포함되어 있는 것이다. 예를 들면, 클라이언트는 주문을 조회하기 위해 보내진 GET 요청에 대한 응답으로 반환된 Order 표현에 있는 링크를 사용하여 주문을 취소할 수 있다. HATEOAS의 장점은 클라이언트 코드 내에 더 이상 URL을 고정하지 않아도 된다는 것이다. 또다른 장점은 리소스의 표현이 처리 가능한 동작을 담고 있기 때문에 클라이언트는 현재 상태에서 리소스가 어떤 동작을 수행할 수 있을지를 추측할 필요가 없다는 것이다.
HTTP에 기반한 프로토콜을 사용하는 것은 많은 장점이 있다.
- HTTP는 익숙하고 단순하다.
- Postman과 같은 Extension을 사용하여 브라우저에서 테스트하거나 curl을 사용하여 커맨드 라인에서(JSON이나 다른 텍스트 포맷을 사용하여) HTTP API를 테스트할 수 있다.
- Request/Response 형태의 통신을 직접 지원한다.
- 물론 HTTP는 방화벽과도 잘 어울린다.
- 중개 브로커가 필요 없다. 따라서 시스템 아키텍처가 간단해진다.
HTTP를 사용할 경우, 단점들도 있다.
- 단지 직접적으로 Request/Response 형태의 상호 작용만 지원한다. HTTP를 사용하여 notification을 보낼 수 있지만, 서버는 항상 HTTP 응답을 보내야 한다.
- 클라이언트와 서버과 직접 통신하기 때문에 (메시지를 버퍼링하기위한 중개자가 없기 때문에) 통신을 교환하는 기간 동안에는 둘 모두 기동되어 있어야만 한다.
- 클라이언트는 각 서비스 인스턴스의 위치를 알고 있어야만 한다. (예를 들면 서버 인스턴스의 URL) 앞의 API Gateway에서 언급된 것처럼, 이것은 현대의 어플리케이션에서 중요한 문제이다. 클라이언트는 서비스 발견 메커니즘을 사용하여 서비스 인스턴스의 위치를 찾야야 한다.
개발자 커뮤니티는 최근에 RESTful API에 대한 인터페이스 정의 언어의 가치를 재발견했다. RAML과 SWagger를 포함하여 몇가지 옵션이 있다. Swagger와 같은 어떤 IDL(Interface Definition Language)에서는 요청/응답 메시지들의 형식을 정의할 수 있다. RAML과 같은 다른 IDL에서는 JSON 스키마와 같은 별도의 표준을 사용하는 것이 필요하다. IDL은 API를 설명하는 것 뿐만 아니라 클라이언트의 Stub과 서버의 Skeleton을 생성하는 도구를 가지고 있다.
Thrift
Apache Thrift는 흥미로운 REST의 대안이다. Thrift는 언어에 무관하게 RPC 클라이언트와 서버를 작성하기 위한 프레임워크이다. Thrift는 API를 정의하기 위한 C 스타일의 IDL을 제공한다. 클라이언트의 Stub과 서버의 Skeleton을 생성하기 위해 Thrift 컴파일러를 사용한다. 컴파일러는 C++, Java, Python, PHP, Ruby, Erlang, Node.js를 포함하여 다양한 언어로 코드를 생성한다.
Thrift 인터페이스는 하나 이상의 서비스로 이루어져 있다. 서비스 정의는 Java 인터페이스와 유사하다. 서비스 정의는 강하게 형식화된 메서드들의 모음이다. Thrift 메서드는 값을 반환(가능하다면 void)하거나 단방향으로 정의할 수 있다. 값을 반환하는 메서드들은 Request/Response 형태의 상호작용을 구현한다. 클라이언트는 응답을 기다리고, 예외를 throw할 수도 있다. 단방향 메서드는 Notification 형태의 상호작용에 해당한다. 서버는 응답을 보내지 않는다.
Thrift는 JSON, Binary(바이너리), Compact Binary(압축 바이너리)와 같은 다양한 메시지 포멧을 지원한다. 바이너리는 JSON보다 디코딩이 더 빠르기 때문에 더 효율적이다. 그리고 이름에서 알 수 있는 것처럼, 압축 바이너리는 공간 효율적인 형식이다. 물론 JSON은 인간과 브라우저에 친화적이다. Thrift는 또한 원시 TCP, HTTP를 포함하여 전송 프로토콜을 선택할 수 있다. 원시 TCP는 HTTP보다 더 효율적이지만, HTTP가 방화벽과 브라우저, 인간에게 더 친화적이다.
Message Formats
(메시지 형식)
HTTP와 Thrift를 살펴 보았다. 이제 메시지 형식에 대한 이슈를 살펴보자. Messaging System이나 REST를 사용할 경우, 메시지 형식을 선택하게 된다. Thrift와 같은 다른 IPC 메커니즘은 소수의 메시지 형식, 아마도 단 한가지 메시지 형식만을 지원할 것이다. 어떤 경우이든, 언어에 무관한 메시지 형식을 사용하는 것이 중요하다. 지금은 한가지 언어로 microservice를 작성했을지라도, 미래에는 다른 언어들을 사용하게 될 것이다.
주요 메시지 형식에는 텍스트와 바이너리 2가지가 있다. 텍스트 기반 형식의 예제로는 JSON과 XML이 있다. 이 형식의 장점으로는 인간이 읽을 수 있을 뿐만 아니라 스스로 설명할 수 있다는 것이다. JSON에서는 객체의 속성을 name-value 쌍의 모음으로 표현한다. 유사하게 XML에서는 속성을 명명된 요소와 값으로 표현한다. 이것은 메시지 Consumer가 관심있는 값을 선택하고 나머지는 무시할 수 있다. 따라서 메시지 형식의 작은 변경만으로 이전 버전과 쉽게 호환할 수 있다.
XML 문서 구조는 XML 스키마로 정의한다. 시간이 지나, 개발자 커뮤니티는 JSON 또한 유사한 메커니즘이 필요하다는 것을 알게 되었다. 하나의 옵션은 독립적이거나 Swagger와 같은 IDL의 일부로 JSON 스키마를 사용하는 것이다.
텍스크 기반 메시지 형식을 사용하는 것의 단점은 특히 XML에서 메시지가 장황하게 되는 경향이 있다는 것이다. 메시지가 스스로 설명할 수 있고, 모든 메시지가 값 이외에 추가로 속성의 이름을 포함하고 있기 때문이다. 또다른 단점은 텍스트 파싱에 따른 오버헤드이다. 따라서, 바이너리 포맷을 사용하는 것을 고려하는 것이 좋을 수도 있다.
선택할 수 있는 바이너리 포맷이 몇가지 있다. Thrift RPC를 사용한다면, 바이너리 Thrift를 사용할 수 있다. 메시지 형식을 선택하는 경우, 유용한 옵션에는 Protocol Buffer와 Apache Avro가 있다. 두가지 모두 메시지 구조를 정의하기 위해 형식화된 IDL을 제공한다. 그러나 한가지 차이점은 Protocol Buffer는 태그가 지정된 필드를 사용하지만, Avro Consumer는 메시지를 해석하기 위해 스키마를 알아야 한다는 것이다. 결과적으로 Avro보다 Protocol Buffer를 사용할 때, API 진화가 더 쉽다. 이 블로그 포스트는 Thrift와 Protocol Buffer, Avro를 훌륭하게 비교했다.


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/763