Service Instance per Host Pattern
(호스트별 단일 서비스 인스턴스 패턴)
Microservice를 배포하는 또 다른 방법은 호스트 별로 하나의 서비스 인스턴스를 배포하는 패턴이다. 이 패턴을 사용할 때, 각 서비스 인스턴스는 자체 호스트에서 독립적으로 실행된다. 이 패턴에는 VM(Virtual Machine)별 서비스 인스턴스 배포 패턴과 컨테이너별 서비스 인스턴스 배포 패턴의 2가지 다른 특별한 유형이 있다.
Service Instance per Virtual Machine Pattern
(Virtual Machine별 서비스 인스턴스 패턴)
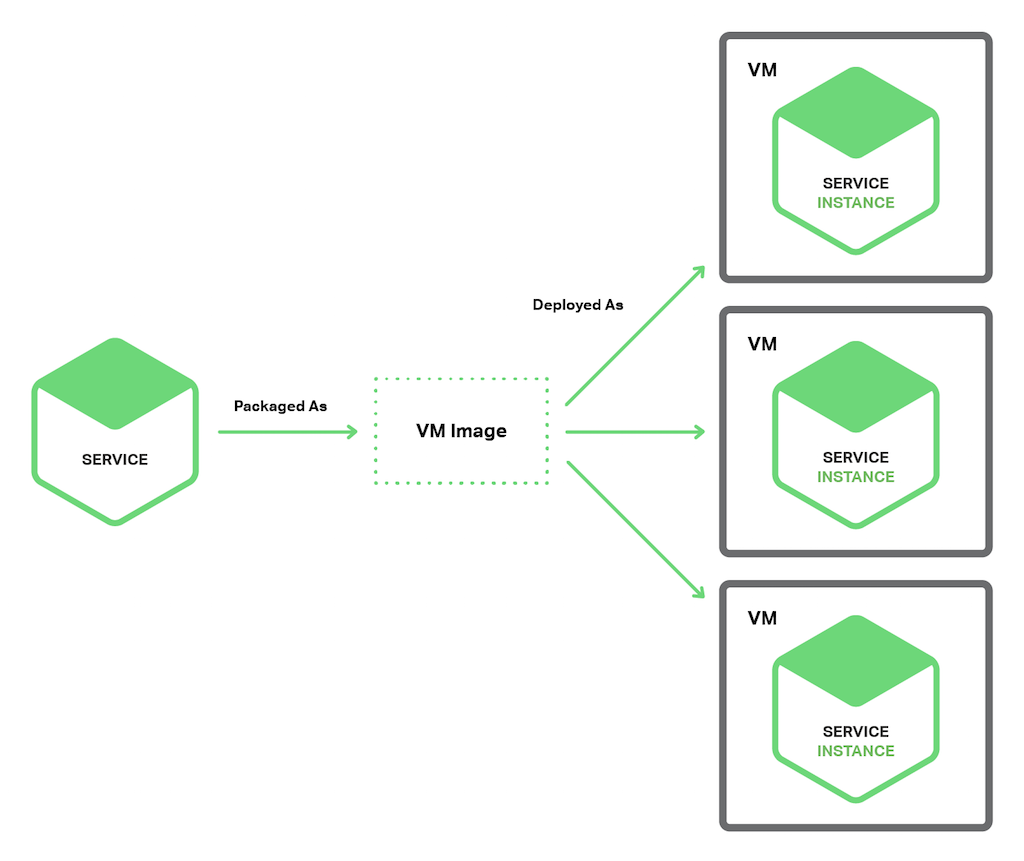
VM별 서비스 인스턴스 배포 패턴을 사용하면, 각 서비스를 아마존 EC2 AMI처럼 VM 이미지로 패키징한다. 가거 서비스 인스턴스는 VM 이미지를 사용하여 실행되는 VM(예를 들면, EC2 인스턴스)이다. 다음 다이어그램은 이 패턴의 구조를 보여준다.
이것은 Netflix에서 비디오 스트리밍 서비스를 배포하기 위해 사용했던 기본 접근 방법이다. Netflix는 Aminator를 사용한 EC2 AMI로 각 서비스를 패키징한다. 실행되는 각 서비스 인스턴스는 EC2 인스턴스이다.
자체 VM을 구축하는데 사용할 수 있는 다양한 툴이 있다. EC2 AMI로 서비스를 패키징하기 위해 Aminator를 호출하여 Continuous Integration (CI, 예 : Jenkins) 서버를 구성할 수 있다. Packer.io는 자동으로 VM 이미지를 생성하기 위한 또다른 옵션이다. Aminator와는 다르게, Packer.io는 EC2, DigitalOcean, ViurualBox, VMWare를 포함하여 다양한 가상화 기술을 지원한다.
Boxfuse 회사는 위에서 언급한 VM들의 단점을 극복한 강력한 VM 이미지 구축 방법을 가지고 있다. Boxfuse는 Java Application을 최소한의 VM 이미지로 패키징한다. 이러한 이미지들은 빌드가 빠르고, 부팅도 빠르고, 제한된 공격 영역을 노출하기 때문에 더 안전하다.
CloudNative는 EC2 AMI 생성을 위한 SaaS 제공 업체인 Bakery를 보유하고 있다. Microservice 테스트 단계 패스 이후 Bakery를 호출하도록 CI 서버를 구성할 수 있다. Bakery는 서비스를 AMI로 패키징한다. Bakery와 같은 SaaS 제공 업체를 사용하는 것은 AMI 생성 인프라 구성에 귀중한 시간을 낭비할 필요가 없다는 것을 의미한다.
VM별 단일 서비스 인스턴스 배포 패턴은 많은 장점이 있다. VM의 주요 이점은 각 서비스 인스턴스가 완벽히 독립되어 실행된다는 것이다. 고정된 CPU와 메모리 용량을 가지고, 다른 서비스의 리소스를 도용할 수 없다.
Microservice를 VM으로 배포하는 또다른 장점은 성숙한 클라우드 인프라를 활용할 수 있다는 것이다. AWS와 같은 클라우드는 로드 밸런싱(부하 분산)이나 Auto-Scaling(자동 확장)과 같은 유용한 기능을 제공한다.
또다른 큰 장점은 서비스 구현 기술을 캡슐화 한다는 것이다. 일단 VM으로 서비스가 패키징되면, Black Box(블랙 박스)가 된다. VM을 관리하는 API는 서비스를 배포하는 API가 된다.(VM 관리 API로 서비스를 배포할 수 있다.) 훨씬 간단하고 안정적으로 배포하게 된다.
그러나, Service Instance per Virtual Machine (VM별 서비스 인스턴스 배포) 패턴은 몇 가지 단점이 있다. 한가지 단점은 리소스 사용 관점에서는 덜 효율적이다. 각 서비스 인스턴스는 OS를 포함하여 전체 VM 오버헤드가 있다. 더우기, 일반적인 공용 IaaS에서는 VM은 고정된 크기를 가지고 있으며, VM을 충분히 활용하지 못할 수도 있다.
다른 관점에서 보면, 일반적으로 공용 IaaS는 VM의 사용 여부와 무관하게 과금한다. AWS와 같은 IaaS는 Auto-Scaling을 지원하지만, 수요 변화에 빠르게 반응하는 것은 어렵다. 결과적으로, VM을 과도하게 준비해야 하므로 배포 비용이 증가하게 된다.
이 접근 방법의 또 다른 단점은 새로운 버전의 서비스를 배포하는 것이 일반적으로 느리다는 것이다. VM 이미지는 크기 때문에 빌드 속도가 느리다. 또한, 크기 때문에 VM은 인스턴스화 하는 것도 느리다. 그리고 OS는 시작하는데 약간 시간이 걸린다. 그러나, Boxfuse로 빌드된 경량화된 VM들이 존재하기 때문에 보편적이라고 말하기는 어렵다.
Service Instance per Virtual Machine 패턴의 또다른 단점은 일반적으로 여러분(혹은 조직의 다른 사람)이 많은 구분되지 않은 들어올리기 힘든 일을 감당한다는 것이다. VM을 빌드하고, 관리하는 오버헤드를 처리하기 위해 Boxfuse와 같은 툴을 사용하지 않는다면, 모두 여러분의 책임이다. 이렇게 필수적이지만 시간을 소모하는 활동은 핵심 비즈니스에서 (여러분의 관심사를) 다른 곳으로 돌린다.
자, 이제 더 가볍고 VM의 많은 이점을 갖는 Microservice 배포에 대한 대안을 살펴보자.
Service Instance per Container Pattern
(컨테이너별 서비스 인스턴스 패턴)
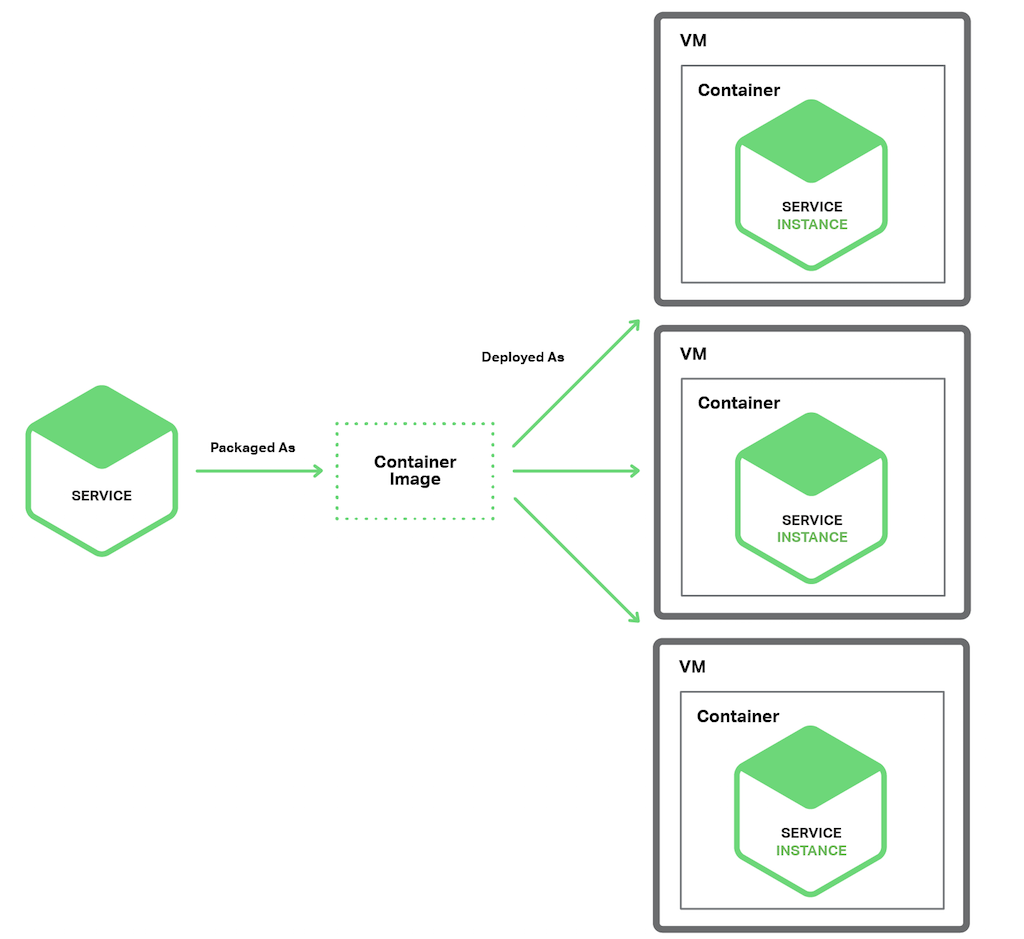
Service Instance per Container (컨테이너별 서비스 인스턴스) 패턴을 사용하는 경우, 각 서비스 인스턴스는 자체 컨테이너에서 동작한다. 컨테이너는 OS 수준 가상화 메커니즘이다. 컨테이너는 샌드박스 내에서 실행되는 하나 이상의 프로세스로 이루어져 있다. 프로세스 관점에서, 프로세스는 자체 포트 네임스페이스와 루트 파일 시스템을 가지고 있다. 컨테이너별로 메모리와 CPU 리소스를 제한할 수 있다. 어떤 컨테이너 구현체에는 I/O 비율 제한도 있다. 컨테이너 기술의 예로 Docker와 Solaris Zones가 있다.
다음 다이어그램에서는 이 패턴의 구조를 보여준다.
이 패턴을 사용하기 위해서는 서비스를 컨테이너 이미지로 패키지해야 한다. 컨테이너 이미지는 Application과 서비스 실행에 필요한 라이브러리들로 구성된 파일 시스템 이미지이다. 일부 컨테이너 이미지는 완전한 리눅스 루트 파일 시스템으로 이루어져 있다. 다른 것들은 더 가볍다. 예를 들면, Java 서비스를 배포하기 위해서 Java Runtime(아마도 Apache Tomcat 서버)과 컴파일된 Java Application을 포함하여 컨테이너 이미지를 빌드 한다.
일단, 서비스를 컨테이너 이미지로 패키징하면 하나 이상의 컨테이너를 실행한다. 각 실제 서버 혹은 가상 서버에서 일반적으로 여러 개의 컨테이너를 실행한다. 컨테이너들을 관리하기 위해서 Kubernetes나 Marathon과 같은 클러스터 관리자를 사용할 수도 있다. 클러스터 관리자는 호스트를 리소스 풀(pool)로 다룬다. 컨테이너가 필요로하는 리소스와 각 호스트에서 이용가능한 리소스를 기반으로 각 컨테이너를 어디에 배치할 지를 결정한다.
Service Instance per Container(컨테이너별 서비스 인스턴스) 패턴은 장단점이 모두 있다. 컨테이너의 장점은 VM과 유사하다. 서비스 인스턴스가 서로 격리되어 있다. 각 컨테이너가 사용하는 리소스를 쉽게 모니터링 할 수 있다. 또한 VM처럼, 컨테이너는 구현된 서비스를 캡슐화한다. 서비스를 관리하기 위한 API로 컨테이너 관리 API를 제공한다.
그러나 VM과는 다르게, 컨테이너는 가벼운 기술이다. 컨테이너 이미지는 일반적으로 매우 빠르게 빌드된다. 예를 들면, 랩톱에서 Spring Boot Application을 Docker 컨테이너로 패키징하는데 약 5초가 걸린다. 지루한 OS 부팅 메커니즘이 없기 때문에 컨테이너는 매우 빠르게 시작된다. 컨테이너가 시작될 때, 서비스도 시작된다.
컨테이너를 사용하는 것에는 몇 가지 단점이 있다. 컨테이너 인프라스트럭처가 급속도로 성숙하고 있으나, VM만큼 성숙하지는 못했다. 또한, 컨테이너들은 호스트 서버 OS의 커널을 서로 공유하므로 VM만큼 안전하지 못하다.
컨테이너의 또다른 단점은 컨테이너 이미지를 관리하는데 구분되지 않은 들어올리기 힘든 책임이 있다는 것이다. 또한 Google Container Engine이나 Amazon EC2 Container Service(ECS)와 같은 호스팅되는 컨테이너 솔루션을 이용하지 않는다면, 컨테이너 인프라와 실행되는 VM 인프라를 관리해야만 한다.
그리고, 컨테이너는 종종 VM 단위 과금되는 인프라에 배포된다. 결과적으로, 앞에서 언급한 것처럼, 급증한 부하를 처리하기 위하여 과도하게 VM을 준비하여 초과 비용을 초래할 수도 있다.
흥미롭게도, 컨테이너와 VM 사이의 차이점이 모호해질 수도 있다. 앞에서 언급한 것처럼, Boxfuse VM은 빠르게 빌드하고 빠르게 시작할 수 있다. Clear Container 프로젝트의 목표는 가벼운 VM을 생성하는 것이다. unikernel에 대한 관심도 증가하고 있다. Docker, Inc는 최근에 Unikernel Systems를 인수했다.
또한 Server-less 배포에 대한 새롭고 인기가 증가하고 있는 개념도 있다. 이 개념은 서비스를 배포하기 위해 컨테이너나 VM 중에 선택하는 이슈를 회피하는 접근 방법이다. 다음에서 살펴보자
트랙백 주소 :: http://www.yongbi.net/trackback/779
트랙백 RSS :: http://www.yongbi.net/rss/trackback/779


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/780