The Drawbacks of Microservices (Microservice의 단점)
약 30년 전, Fred Brooks가 쓴 것처럼, 획기적인 방법은 없다. 다른 모든 기술들처럼 Microservice Architecture도 단점이 있다. 한가지 단점은 이름 그 자체에 있다. Microservice라는 용어는 서비스의 크기를 과도하게 강조한다. 사실, 극도로 잘게 나누어진, 10~100줄의 코드로 이루어진 서비스 개발을 지지하는 개발자들도 있다. 작은 서비스들이 더 좋지만, 그것은 목적을 위한 수단이고, 주된 목적은 아니라는 것을 기억하는 것이 중요하다. Microservice의 목적은 어플리케이션을 빠르게 개발하고 배포 가능하도록 하기 위하여 어플리케이션을 충분히 분해하는 것이다.
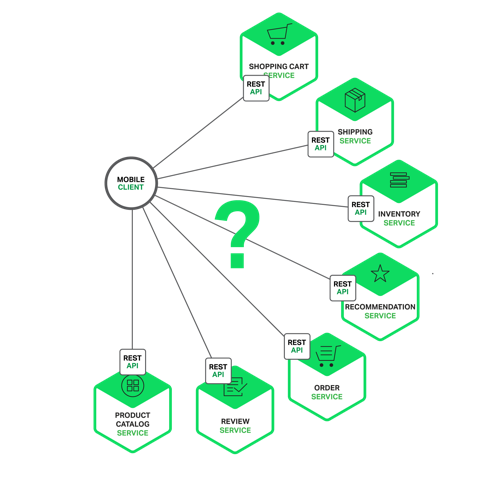
Microservice의 또다른 주요 단점은 microservice 어플리케이션들이 분산환경에 있다는 사실에서 발생하는 복잡성에 있다. 개발자들은 메시지나 RPC중 하나에 기반한 inter-process communication 메커니즘을 선택하고 구현할 필요가 있다. 더욱이, 요청의 목적지가 느려지거나 이용불가능할 경우가 있기 때문에 부분적인 오류를 다루는 코드를 반드시 작성해야만 한다. 고도의 지능이 요구되는 일은 아니지만, 모듈간 language-level method/procedure 호출을 통해 서로 통신하는 monolithic application에서 훨씬 더 복잡하다.
(Inter-process communication : 프로세스들 사이에 서로 데이터를 주고 받는 통신 방법 혹은 경로)
Microservice의 또다른 도전은 분할된 데이터베이스 구조(partitioned database architecture)이다. 일반적으로 Business Transaction은 여러 개의 business entity들을 업데이트한다. 이러한 종류의 transaction들을 monolithic application에서 구현하는 것은 사소한 일이다. 왜냐하면, 하나의 데이터베이스만 있기 때문이다. 그러나 Microservice 기반 application 에서는 다른 서비스들이 소유한 여러 개의 데이터베이스를 업데이트할 필요가 있다. 분산 transaction을 사용하는 것은 CAP theorem 때문에 유일한 해결책은 아니다. 오늘날 매우 확장 가능한 많은 NoSQL 데이터베이스나 messaging broker에서 분산 transaction을 지원하지 않는다. 결국 개발자들에게 더 도전적인, 궁극적인 일관성에 기반한 접근법을 사용해야만 하는 상황에 직면하게 된다.
Microservice 어플리케이션을 테스트하는 것 또한 훨씬 더 복잡하다. 예를 들면, Spring Boot과 같은 최근의 framework으로 monolithic 웹 어플리케이션을 구동하는 테스트 클래스를 작성하고, REST API를 통해서 테스트 하는 것은 사소한 일이다. 반대로, 서비스에 대한 유사한 테스트 클래스는 테스트 대상 서비스와 의존 관계에 있는 다른 서비스들을 실행할 필요가 있다.(최소한 그러한 서비스들에 대한 stub 환경 설정이라도 해야 한다.) 한번 더 말하면, 이것이 고도의 지능을 요구하는 일은 아니지만, 테스트 수행에 대한 복잡도를 너무 적게 잡지 않는 것이 중요하다. (테스트 수행이 monolithic application 보다 복잡하다는 뜻.)
Microservice Architecture Pattern의 또 다른 주요 도전은 여러 서비스에 퍼져 있는 변경 사항들을 구현하는 것이다. 예를 들어, 서비스 A, B, C의 변경을 요구하는 스토리를 구현하는 것을 상상해 보자.서비스 A는 서비스 B에 의존하고, 서비스 B는 서비스 C에 의존한다. Monolithic application 에서는 해당 모듈들을 간단하게 변경하고, 변경 사항들을 취합하여 한번에 배포할 수 있다. 반대로, Microservice Architecture Pattern 에서는 주의하여 계획을 세우고, 뽑아낸 변경사항들에 대해 각 서비스들을 조정, 반영해야 한다. 예를 들어, 서비스 C를 업데이트할 필요가 있을 경우, 서비스 B도 따라서 업데이트 하고, 마지막으로 서비스 A도 업데이트 해야 한다. 다행스럽게도 대부분의 변경사항들은 보통 하나의 서비스에만 영향을 주고 조정이 필요한 여러 서비스를 변경하는 경우는 거의 드물다.
Microservice 기반 어플리케이션을 배포하는 것은 훨씬 더 복잡하다. Monolithic 어플리케이션은 전통적인 load balancer 뒤에 있는 동일한 서버에 간단하게 배포된다. 각각의 application instance에는 데이터베이스와 messaging broker와 같은 infrastructure service의 위치(host and ports)가 설정되어 있다. 반대로, microservice application은 일반적으로 수많은 서비스들로 이루어져 있다. 예를 들어, Hailo는 160개의 다른 서비스들로 이루어져 있고, Netflix는 Adrian Cockcroft에 따르면 600개가 넘는다. 각 서비스는 여러 개의 runtime instance를 가지고 있을 것이다. 여기에는 설정하고, 배포하고, 확장하고, 모니터링 대상이 되는 많은 이동하는 부품들이 있다. 게다가, 하나의 서비스에서 통신할 필요가 있는 다른 서비스들의 위치(host and ports)를 찾기 위한 service discovery mechanism(나중에 다른 post에서 논의할 것이다.)을 구현할 필요가 있다. 전통적인 trouble ticket 기반과 operation에 대한 수작업 접근법은 복잡도의 레벨을 변경할 수 없다. 따라서, microservice application 을 성공적으로 배포하는 것은 개발자들이 배포 방법을 더 많이 제어하고, high level 자동화가 필요하다.
자동화에 대한 한가지 접근 방법은 Cloud Foundry와 같은 기성 PaaS를 이용하는 것이다. PaaS는 개발자들이 microservice를 배포하고 관리하는 데 쉬운 방법을 제공한다. PaaS는 IT 리소스를 어렵게 구하고 설정하는 것에 대한 우려를 불식시킨다. 동시에, PaaS를 설정하는 시스템과 네트워크 전문가들은 best practice와 회사 정책에 따른 법규 준수를 보장할 수 있다. Microservice 배포를 자동화하는 또다른 방법은 근본적으로 여러분 자신의 PaaS를 개발하는 것이다. 한가지 전형적인 시작 포인트는 Docker와 같은 기술과 함께 Kubernetes와 같은 클러스터링 솔루션을 이용하는 것이다. 이 시리즈의 뒤쪽에서, Microservice level에서 caching, access control, API metering, monitoring을 쉽게 다루는 NGINX와 같은 software 기반 어플리케이션 배포 방법들이 이 문제를 해결하는데 어떤 도움을 줄 수 있는지를 보여줄 것이다.
트랙백 주소 :: http://www.yongbi.net/trackback/750
트랙백 RSS :: http://www.yongbi.net/rss/trackback/750


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/753