Amazon, eBay, Netflix 같은 많은 조직들에서 Microservice Architecture Pattern이라고 알려져 있는 기술을 채택하여 이러한 문제를 해결하고 있다. Microservice
Architecture는 하나의 괴물같은 monolithic application을 만드는 대신에, 더 작고 서로 연결되어 있는 서비스들의 집합으로 application을 나누는 것이다.
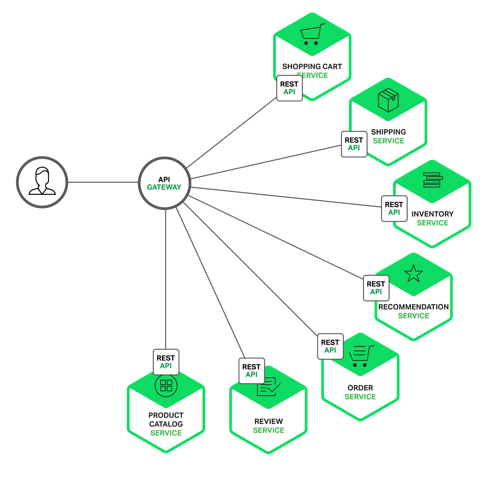
일반적으로 서비스는 order management(주문관리),
customer management(고객관리), 등과 같은 별개의 특징이나 기능 집합으로 구현되어 있다. 각각의 microservice는 그 자체에 다양한 어댑터에 대한 비즈니스 로직을 가진 6각형의 아키텍처를 가지는 mini-application이다. 어떤 microservice는 다른 microservice나 application client에 의해서 호출되는 API를 제공하고, 다른 microservice는 Wen UI를 구현할 수도 있다.
런타임시에는 각각의 instance는 클라우드 VM이나 Docker container 상에 실행되기도 한다.
예를 들면, 앞서 기술된 시스템을 분해하면, 다음과 같은 다이어그램으로 표현할 수 있다.
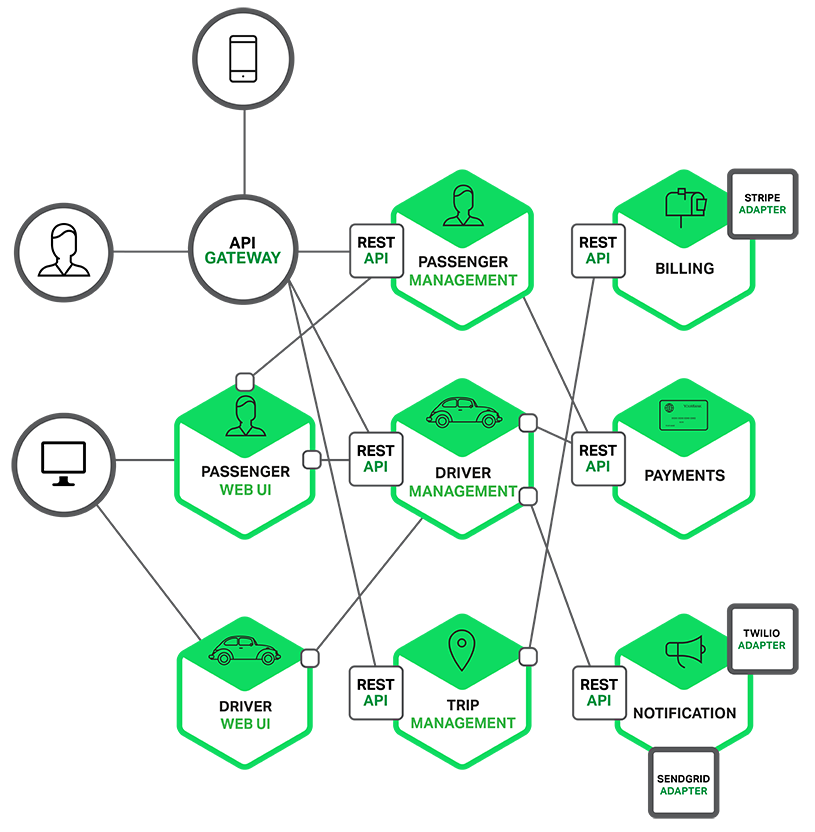
Application의 개별 기능은 각각의 microservice로 구현되어 있다. 더욱이 web application은 더 간단한 web application의 집합으로 나누어져 있다. (택시 호출 서비스 예제에서 보면, 한 명의 운전 기사가 한 명의 승객과 매칭되는 경우). 이것은 특정 user, device, 혹은 특별한 use case별로 개별 경험을 더 쉽게 배포하게 한다.
각 backend service는 REST API를 제공하고, 대부분의 service들은 다른 service가 제공하는 API를 사용한다. 예를 들어, Driver Management(기사 관리)는 잠재적 이동에 대해 활동 가능한 운전 기사에게 알려주는데 Notification
Server를 사용한다. UI service들은 web page들을 렌더링하기 위해 다른 서비스들을 호출한다. 서비스들은 메시지 기반의 communication에 async방식을 사용한다. 서비스간의 communication에 대해서는 추가로 나중에 자세히 다룰 것이다.
몇몇 REST API는 기사나 승객에 의해 사용되는 mobile app에서 이용한다. 그러나 이러한 app들은 backend service이 직접 접속할 수 없다. 대신에 communication은 API
Gateway로 알려진 중재자를 통해 가능하게 된다. API Gateway는 로드밸런싱, caching, access control, API metering, monitoring과 같은 부분들을 처리해야 한다. 이러한 부분들은 nignx를 사용하여 효과적으로 구현할 수 있다.
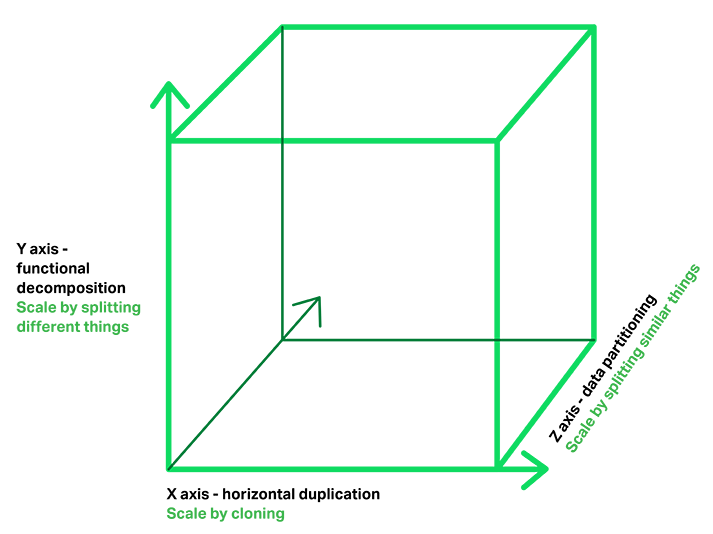
Microservice architecture pattern은 scalability(확장성) 3D
Model에 대한 최고의 책인 "The Art of Scalability"에 나오는 Scale Cube의 Y축 Scaling에 대응된다. 다른 2개의 Scaling 축은 load
balancer 뒤에서 실행중인 여러 개의 동일한 application 복사본으로 구성된 X축 Scaling과 요청의 속성(예를 들면, row의 primary key나 고객의 identity)이 특정 서버에 대한 요청으로 route하는데 사용되는 Z축 Scaling(혹은 data
partitioning)이 있다.
Application들은 일반적으로 3가지 Scaling 타입을 함께 사용한다. Y축 Scaling은 이 섹션 첫번째 그림에서 보여주는 대로 application을 microservice로 분해한다. Runtime 시점에 X축 Scaling은 load balancer 뒤에서 처리량과 가용성을 위해 각 서비스에 대해 여러 개의 instance를 실행한다. 어떤 application들은 service를 partition하기 위해 Z축 Scaling을 사용하기도 한다.
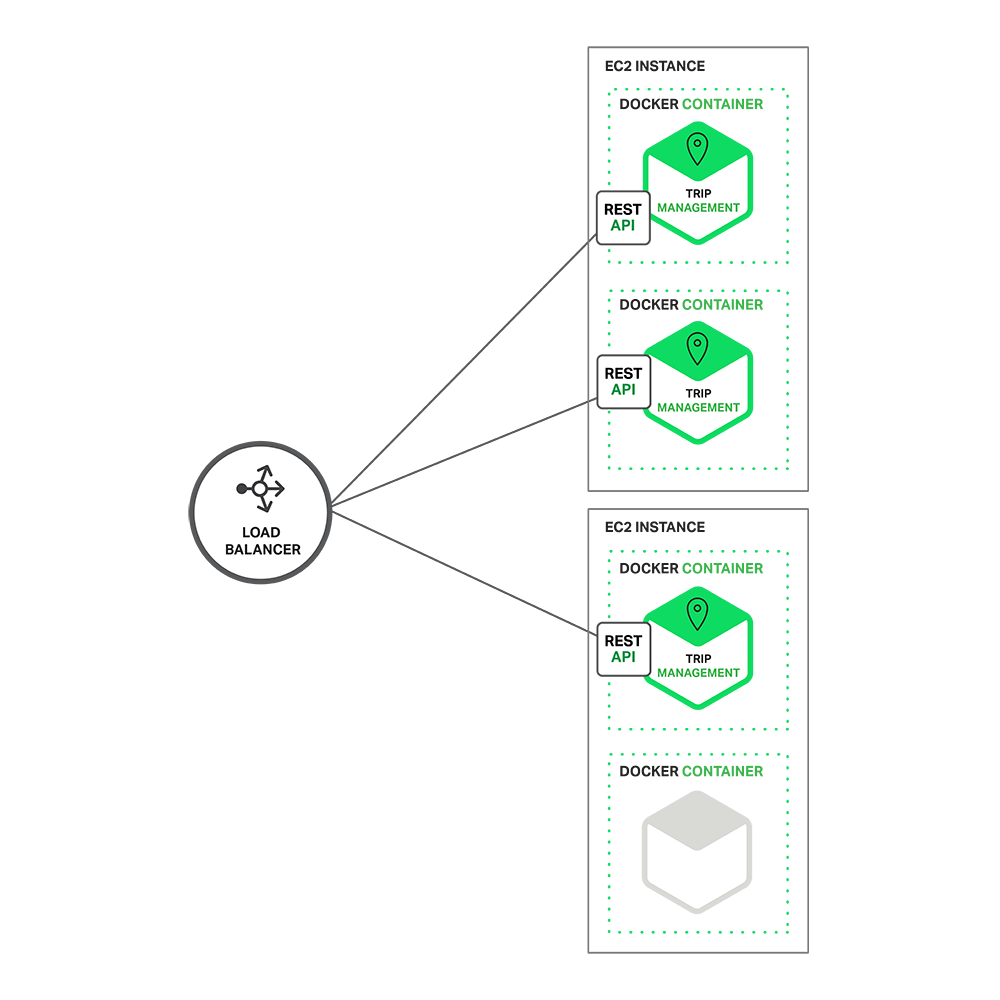
다음 다이어그램은 Trip Management 서비스가
Amazon EC2 서버 상에 Docker로 어떻게 배포되는지를 보여준다.
Runtime시에 Trip
Management 서비스는 여러 개의 instance로 구성되어 있다. 각 서비스 instance는 Docker container로 제공된다. 가용성을 높이기 위해서 docker container들은 여러 개의 cloud VM에서 돌아간다. Service instance 앞단에는 여러 instance로 요청을 분산하는 nginx와 같은 load balancer가 있다. Load balancer는 caching, access control, API metering,
monitoring과 같은 여러 가지 관심 사항들을 취급할 수 있어야 한다.
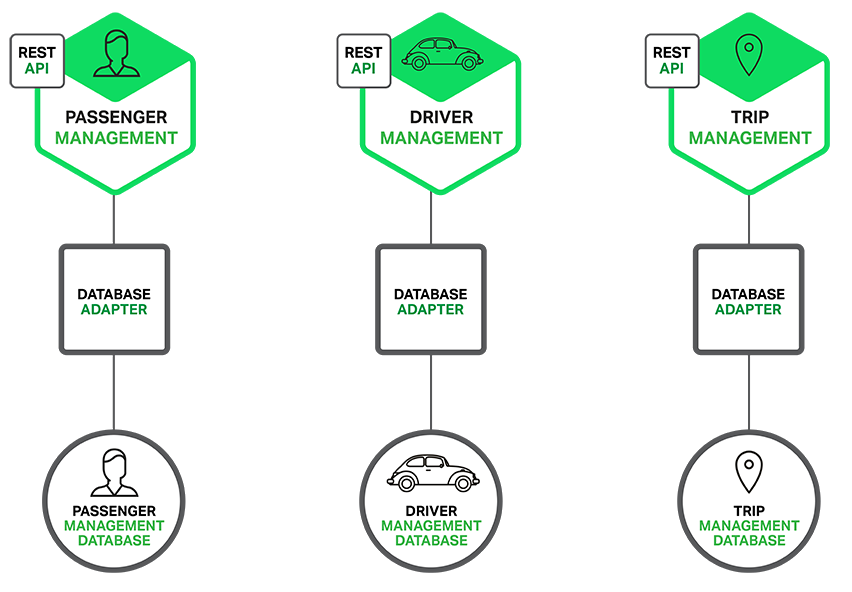
Microservice Architecture Pattern은 특히 application과 database 사이의 관계에 중요한 영향을 준다. 서로 다른 service간 하나의 database schema를 공유하는 것보다는 각각의 서비스가 독자적인 database schema를 갖는다. 다른 한편으로 이러한 접근은 Enterprise-Data Model 관점에서는 이상하다. 또한, 어떤 데이터들은 종종 중복되기도 한다. 그러나 서비스별 database schema를 갖는 것은 microservice를 통해 혜택을 보기 원한다면, 본질적인 부분이다. 왜냐하면, microservice는 느슨한 연결(loose coupling)을 보장하기 때문이다. 다음 다이어그램은 예제로 제시된 application에 대한 database architecture를 보여주고 있다.
각각의 서비스는 자체적으로 데이터베이스를 가지고 있다. 게다가, 서비스별로 소위 polyglot
persistence architecture(상황에 맞게 최적화된 구조로 데이터를 구분하여 저장하는 아키텍처)라고 불리는 가장 최적의 데이터베이스 타입을 사용할 수 있다.
예를 들어, 잠재적인 승객에게 가장 가까운 운전 기사들을 찾아야 하는 Driver Management(기사 관리)는 geo-query(지리기반 질의)를 지원하는 데이터베이스를 사용해야만 한다. 표면적으로는 MSA는 SOA와 유사하다. 두가지 모두 서비스들의 집합으로 구성된 아키텍처이다. 하지만, MSA는 WS 표준과 ESB가 없는 SOA라고 생각하면 된다.
Microservice 기반
application은 WS 표준보다 굉장히 단순하고, REST와 같은 가벼운 프로토콜을 사용한다. 또한 ESB 사용을 지양하고, microservice 자체적으로
ESB 유사한 기능을 구현한다. Microservice
Architecture Pattern은 정규 스키마(canonical schema)와 같은 SOA의 다른 부분도 거부한다.


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/754