(클라이언트 측면의 검색 패턴)
클라이언트 측 검색을 사용할 때, 클라이언트는 사용 가능한 서비스 인스턴스의 네트워크 위치를 결정하고, 인스턴스들 사이의 요청에 대한 부하 분산을 담당한다. 클라이언트는 이용 가능한 서비스 인스턴스들의 데이터베이스인 서비스 레지스트리(서비스 등록소)를 조회한다. 그런 다음 클라이언트는 이용 가능한 서비스 인스턴스 중에 로드밸런싱 알고리즘을 사용하여 하나를 선택하고, 요청한다.
다음 다이어그램은 이 패턴의 구조를 보여준다.
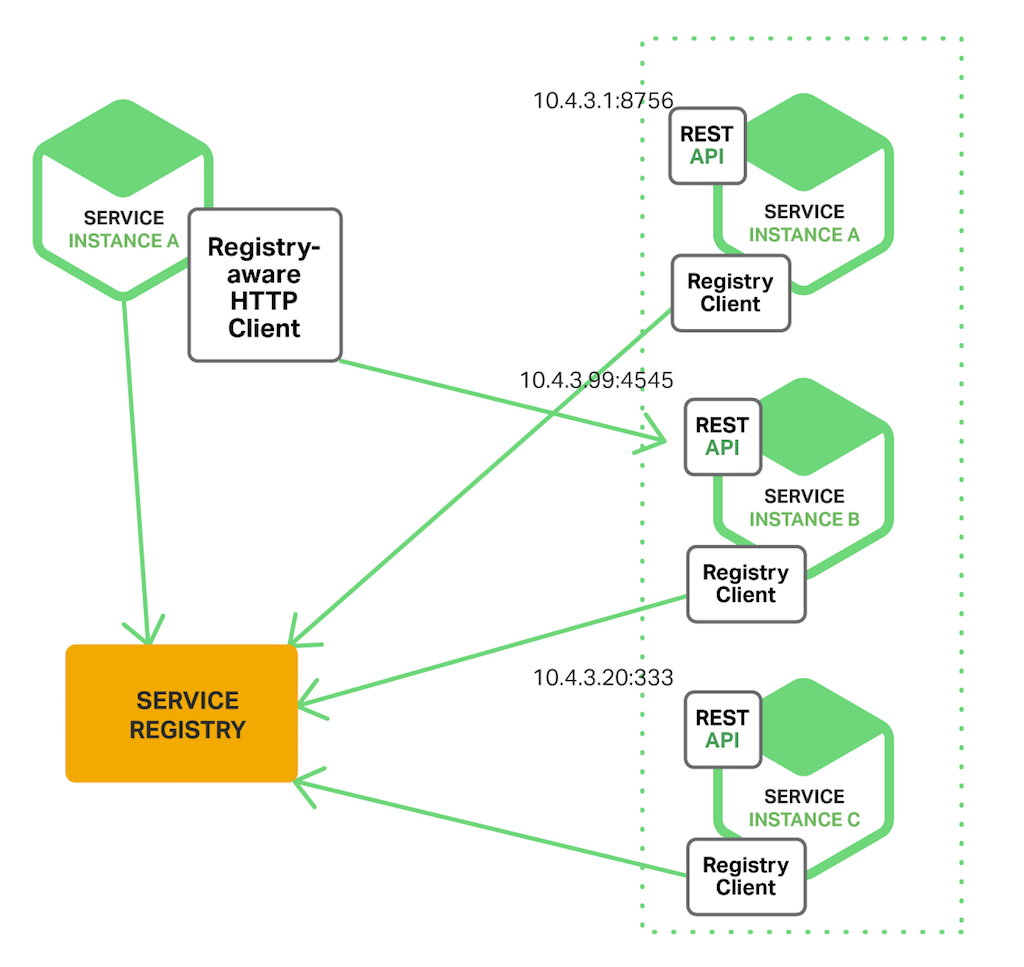
서비스 인스턴스의 네트워크 상 위치는 서비스가 시작될 때, 서비스 레지스트리에 등록되고, 서비스 인스턴스가 종료될 때, 서비스 레지스트리에서 삭제된다. 일반적으로 서비스 인스턴스의 등록은 Heart-Beat 메커니즘을 사용하여 주기적으로 갱신된다.
Netflix OSS는 클라이언트 측면에서의 검색 패턴의 좋은 예제이다. Netflix Eureka는 서비스 레지스트리이다. 서비스 인스턴스 등록을 관리하고 이용 가능한 서비스 인스턴스를 조회할 수 있도록 REST API를 제공한다. Netflix Ribbon은 이용 가능한 서비스 인스턴스들 사이에 요청을 분산하기 위해 Eureka와 함께 사용하는 IPC 클라이언트이다. 이 기사(article)의 뒷부분에 Eureka에 대해서 더 깊이 다룰 것이다.
클라이언트 측면의 검색 패턴은 다양한 장점과 단점이 있다. 이 패턴은 상대적으로 간단하고, 서비스 등록을 제외하면 다른 움직이는 부분은 없다. 또한 클라이언트는 이용 가능한 서비스 인스턴스에 대해 알고 있기 때문에, 일관되게 해싱을 사용하는 것처럼 지능적이고 어플리케이션에 특화된 부하분산 결정을 할 수 있다. 이 패턴의 한가지 중요한 단점은 클라이언트가 서비스 레지스트리와 결합되어 있다는 것이다. 서비스 클라이언트에서 사용하는 각 프로그래밍 언어와 프레임워크에 대해 클라이언트 측면의 서비스 검색 로직을 구현해야만 한다.
지금까지 클라이언트 측면의 검색에 대해서 살펴보았다. 이제 서버 측면의 검색에 대해서 살펴보자.


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/766