Introduction to Core Spark Concepts
이제 여러분은 shell을 사용하여 첫번째 Spark Code를 작성하고 실행해 보았다. 이제 programming에 대해서 좀더 상세한 내용을 공부할 시간이다. High level에서 볼 때, 모든 Spark application은 Cluster상에서 다양한 병렬 연산을 수행하는 driver program으로 이루어져 있다. Driver program에는 main 함수와 Cluster상에 분산되어 있는 Dataset에 대한 정의가 포함되어 있고, Dataset에 대한 operation이 담겨져 있다. 앞에서 언급한 예제에서 보면, driver program은 실행하고자 하는 연산에 대한 code를 작성하기만 하면 되는 Spark shell 그 자체이다.
Driver Program은 SparkContext object를 통해서 Spark에 접속한다. SparkContext는 계산하고자 하는 Cluster에 연결하는 것을 나타낸다. Shell에서는 변수 sc를 호출하는 순간 SparkContext가 자동으로 생성된다. 다음과 같이shell에서 sc를 typing해보자.
>>> sc
<pyspark.context.SparkContext object at 0x1025b8f90>
한번 SparkContext를 가져오고 나면, resilient distributed dataset(RDD)을 생성하는데 그것을 사용할 수 있다. 앞의 예제에서는 file내의 text line을 나타내는 RDD를 생성하기 위해서 SparkContext.textFile을 호출했다. 그리고 우리는 lines 상에서(생성한 RDD상에서) count()와 같은 다양한 연산을 수행할 수 있었다.
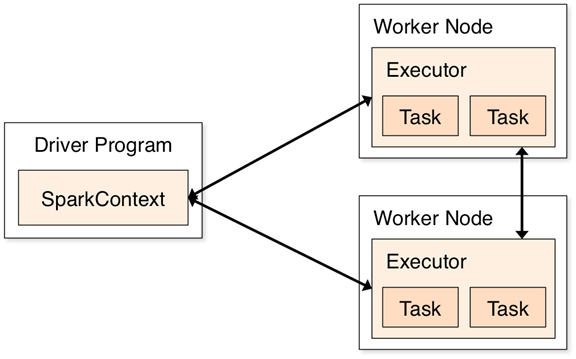
이러한 연산을 수행하기 위해서 driver program은 Executor라고 불리는 여러 node들을 관리한다. 예를 들어, Cluster상에서 count()를 수행하려고 한다면, 서로 다른 machine에서 서로 다른 크기의 file로부터 line을 셀 것이다. 우리는 Spark shell을 local에서 수행했기 때문에 single machine에서 모든 작업을 수행할 것이다. 하지만, Cluster 환경에서 병렬로 데이터를 분석하기 위해서 동일한 shell에 연결할 수 있다. 다음 그림은 Cluster상에서 어떻게 Spark가 동작하는지를 보여준다.
[Components for distributed execution in Spark]
끝으로, 대부분의 Spark API는 Cluster상의 Operator로 작업을 수행하기 위해 전달하는 함수 역할을 수행한다. 예를 들어, "Python"이라는 단어를 포함하고 있는 line을 filtering하기 위해 README example을 확장할 수 있다.
[Python filtering example]
>>> lines = sc.textFile("README.md")
>>> pythonLines = lines.filter(lambda line: "Python" in line)
>>> pythonLines.first()
u'## Interactive Python Shell'
[Scala filtering example]
scala> val lines = sc.textFile("README.md") // Create an RDD called lines
lines: spark.RDD[String] = MappedRDD[...]
scala> val pythonLines = lines.filter(line => line.contains("Python"))
pythonLines: spark.RDD[String] = FilteredRDD[...]
scala> lines.first()
res0: String = ## Interactive Python Shell
(NOTE : lambda에 익숙하지 않거나 => syntax에 익숙하지 않으면, Python이나 Scala 내부에서 함수를 정의하기 위한 축약방식이다. 이러한 언어들을 Spark에서 사용할 때, 분리해서 함수를 정의하고 Spark에 그 이름을 넘겨줄 수도 있다. 예를 들어 Python으로 다음과 같이 작성할 수 있다.
def hasPython(line):
return "Python" in line
pythonLines = lines.filter(hasPython)
Spark에 함수를 넘기는 것은 Java에서도 가능하다. 하지만, 이 경우에는 우리는 class로 정의하고 Function이라고 불리는 인터페이스를 implement해야 한다. 예를 들면 다음과 같다.
JavaRDD<String> pythonLines = lines.filter(
new Function<String, Boolean>() {
Boolean call(String line) { return line.contains("Python"); }
}
);
Java 8에서는 lambdas라고 불리는 축약형 syntax를 소개하고 있다. Python이나 Scala에서 사용하는 방식과 비슷하다. 위와 동일한 기능을 하는 Java lambdas Code는 다음과 같다.
JavaRDD<String> pythonLines = lines.filter(line -> line.contains("Python"));
우리는 나중에 Passing Functions to Spark에서 추가로 논의할 것이다.)
우리는 나중에 Spark API에 대해서 더 자세히 다룰 것이다. Spark API는 cluster상에서 병렬로 처리되는 filter와 같은 함수 기반 operation을 위한 마법과도 같다. Spark는 자동으로 여러분이 작성한 함수(예를 들면, line.contaions("Python"))를 가져다가 executor node에 태운다. 이와 같이 여러분이 하나의 driver program 코드를 작성하면 자동으로 여러 node에서 실행해 준다. Chapter 3에서는 RDD API에 대해서 더 자세히 다룬다.
트랙백 주소 :: http://www.yongbi.net/trackback/658
트랙백 RSS :: http://www.yongbi.net/rss/trackback/658


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/659