Spark는 즉각적인 Data Analysis를 쉽게 할 수 있는 interactive shell을 제공한다. Spark의 shell은 R, Python, Scala와 같은 다른 형태의 shell이나 Bash, windows command prompt와 같은 OS시스템의 shell을 사용해본 경험이 있다면 쉽게 익숙해질 수 있을 것이다.
하지만, 하나의 machine에 있는 disk나 memory에 있는 데이터를 취급하는 대부분의 다른 shell들과는 다르게 Spark의 shell은 여러 machine의 disk나 memory에 분산되어 있는 데이터로 작업할 수 있도록 한다. 그리고 Spark는Data 처리 process를 자동으로 분산처리하고 보호한다.
Spark는 memory로 Data를 load할 수 있기 때문에, 많은 분산 컴퓨팅 환경에서 수초안에 - 심지어 수십대의 machine에서 테라바이트 단위의 data를 처리하는 경우에도 - 처리를 완료할 수 있다. 그러므로 shell을 이용해 sort of iterative, ad-hoc, exploratory analysis를 처리하는 경우에 Spark를 이용해서 처리하는 것이 적합하다. Spark는 Cluster에 연결하는 것을 지원하기 위해 많이 사용하는 Python, Scala shell 모두 지원한다.
[NOTE]
이 책의 대부분의 코드는 Spark에서 지원하는 모든 language로 이루어져 있지만, interactive shell은 Python과 Scala만 이용가능하다. Shell은 API를 배우는데 아주 유용하기 때문에 Java 개발자들도 Python이나 Scala 언어로 모든 example을 사용해 보기를 추천한다. API는 모든 언어에서 동일하다.
Spark's Shell의 power를 설명하는 가장 쉬운 방법은 간단한 data analysis에 사용해 보는 것이다. 공식적인 Spark document에 있는 Quick Start Guide에 있는 example을 돌려보자.
첫번째로 Spark's Shell을 Open한다.
Python version의 Spark Shell을 open하기 위해서는(우리는 PySpark Shell이라고도 부른다.) Spark directory로 들어가서 다음을 치면 된다.
bin/pyspark (윈도우 시스템에서는 bin\pyspark)
Scala version의 Shell을 open하기 위해서는 다음을 친다.
bin/spark-shell
Shell prompt는 몇 초 안에 나타날 것이다. Shell을 시작할 때, 많은 log message를 볼 수 있을 것이다. Log output을 깨끗하게 하기 위해서 [Enter] 키보드를 치면 shell prompt를 볼 수 있다. PySpark Shell을 실행하고 난 후의 화면은 다음 그림과 같다.
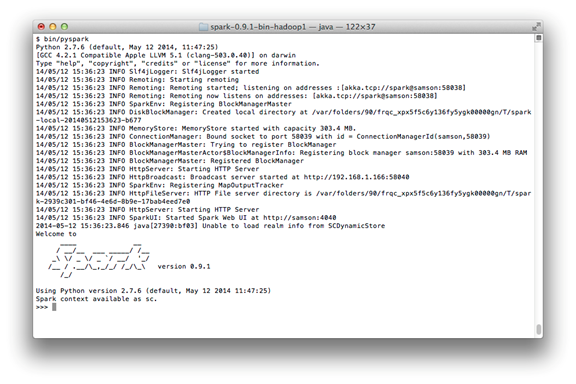
[The PySpark Shell With Default Logging Output]
Shell 내에 주의를 산만하게 하는 화면에 출력된 logging statements를 볼 수 있을 것이다. Logging에 대한 길이를 조절할 수 있다. 이렇게 하기 위해서 conf directory에 log4j.properties 파일을 만들수 있다. Spark 개발자에게는 이미 log4j.properties.template 파일이 포함되어 있다. Logging을 덜 나오게 하려면 conf/log4j.properties.template 파일을 conf/log4j.properties 파일로 복사하고 다음 라인을 찾는다.
log4j.rootCategory=INFO, console
다음과 같이 변경하여 WARN에 대한 message만 보도록 log level을 낮출 수 있다.
log4j.rootCategory=WARN, console
Shell을 다시 open했을 때, 이제는 output이 다음과 같이 나타날 것이다.
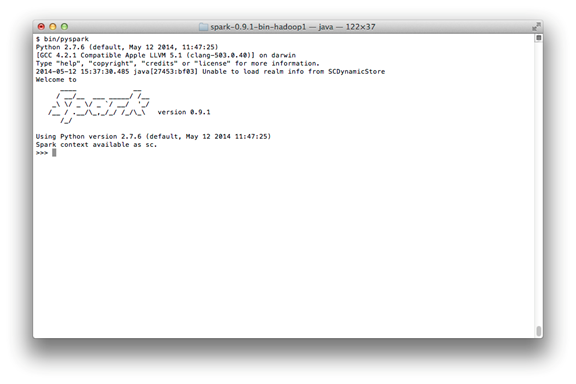
[The PySpark Shell With Less Logging Output]
[IPYTHON 사용]
Ipython은 많은 사용자들이 애용하고 있는 tab 키보드를 치면 이후 문장을 자동으로 완성시켜주는 Python Shell의 확장판이다. 설치에 대한 안내는 http://ipython.org 에서 찾아볼 수 있다. 변수 1에 IPYTHON 환경 설정을 해줌으로써 Spark에서 Ipython을 사용할 수 있다.
IPYTHON=1 ./bin/pyspark
Web 브라우저 버전의 Ipython Notebook을 사용하기 위해서는 다음을 사용하라.
IPYTHON_OPTS="notebook" ./bin/pyspark
윈도우 시스템에서는 환경변수 설정을 다음과 같이 하면 된다.
set IPYTHON=1
bin\pyspark
우리는 Spark를 이용해 Cluster 환경에서 자동으로 분산되어 있는 collection으로부터 계산하는 operation을 수행해 볼 것이다. 이러한 collection을 RDD (Resilient Distributed Dataset)라고 부른다. RDD는 Spark에서 분산되어 있는Data와 계산에 대한 가장 기본적인 추상화 계층이다.
RDD에 대해서 더 자세히 말하기 전에, local text file로 아래와 같이 ad-hoc data analysis하기 위한 하나의 shell을 간단히 작성해 보자.
[Python line count]
>>> lines = sc.textFile("README.md") # Create an RDD called lines
>>> lines.count() # Count the number of items in this RDD
127
>>> lines.first() # First item in this RDD, i.e. first line of README.md
u'# Apache Spark'
[Scala line count]
scala> val lines = sc.textFile("README.md") // Create an RDD called lines
lines: spark.RDD[String] = MappedRDD[...]
scala> lines.count() // Count the number of items in this RDD
res0: Long = 127
scala> lines.first() // First item in this RDD, i.e. first line of README.md
res1: String = # Apache Spark
Shell에서 빠져 나오려면 Ctrl+D를 누르면 빠져나올 수 있다.
위의 예에서, lines라고 불리는 변수는 RDD이고 text file로부터 local machine에 생성된다. 우리는 RDD 상에서 dataset의 구성요소 수를 세거나 (여기서는 text file 내의 line 수), 첫번째 라인을 출력하는 것과 같은 여러 병렬 연산들을 수행할 수 있다. 우리는 다음 장에서 RDD에 대해서 더 깊이 다룰 것이다. 하지만, 더 나아가기 전에 Spark의 기본적인 개념들에 대해서 설명하는 시간을 갖도록 하자.


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/657