Achieving Atomicity
(원자성 달성)
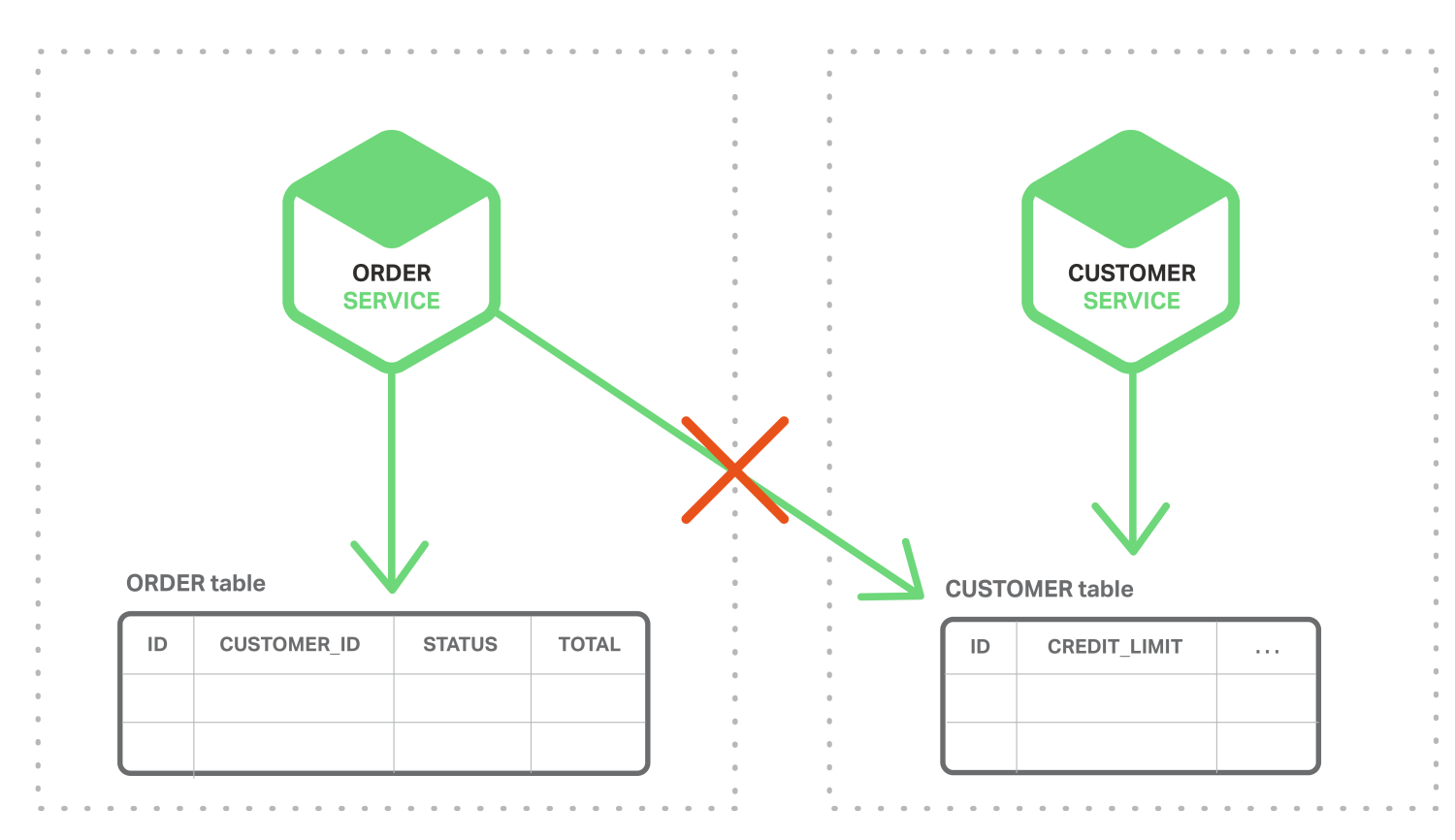
Event-Driven Architecture에서는 데이터베이스를 원자적으로 업데이트하고 이벤트를 게시하는 문제가 있다. 예를 들면, Order Service는 ORDER 테이블에 행을 입력하고, Order Created Event를 게시해야 한다. 이 두가지 작업들은 원자적으로 수행되는 것이 필수적이다. 만약에 데이터베이스를 업데이트하고 이벤트를 게시하기 전에 서비스가 충돌하면 시스템은 데이터 일관성을 잃게 된다. 원자성을 보장하는 표준적인 방법은 데이터베이스와 Message Broker가 분산 트랜잭션을 사용하는 것이다.
그러나, 위에서 언급된 CAP이론과 같은 이유들 때문에 이것은 우리가 정확히 원하지 않는 것이다.
Publishing Events Using Local Transactions
(로컬 트랜잭션을 사용한 이벤트 게시)
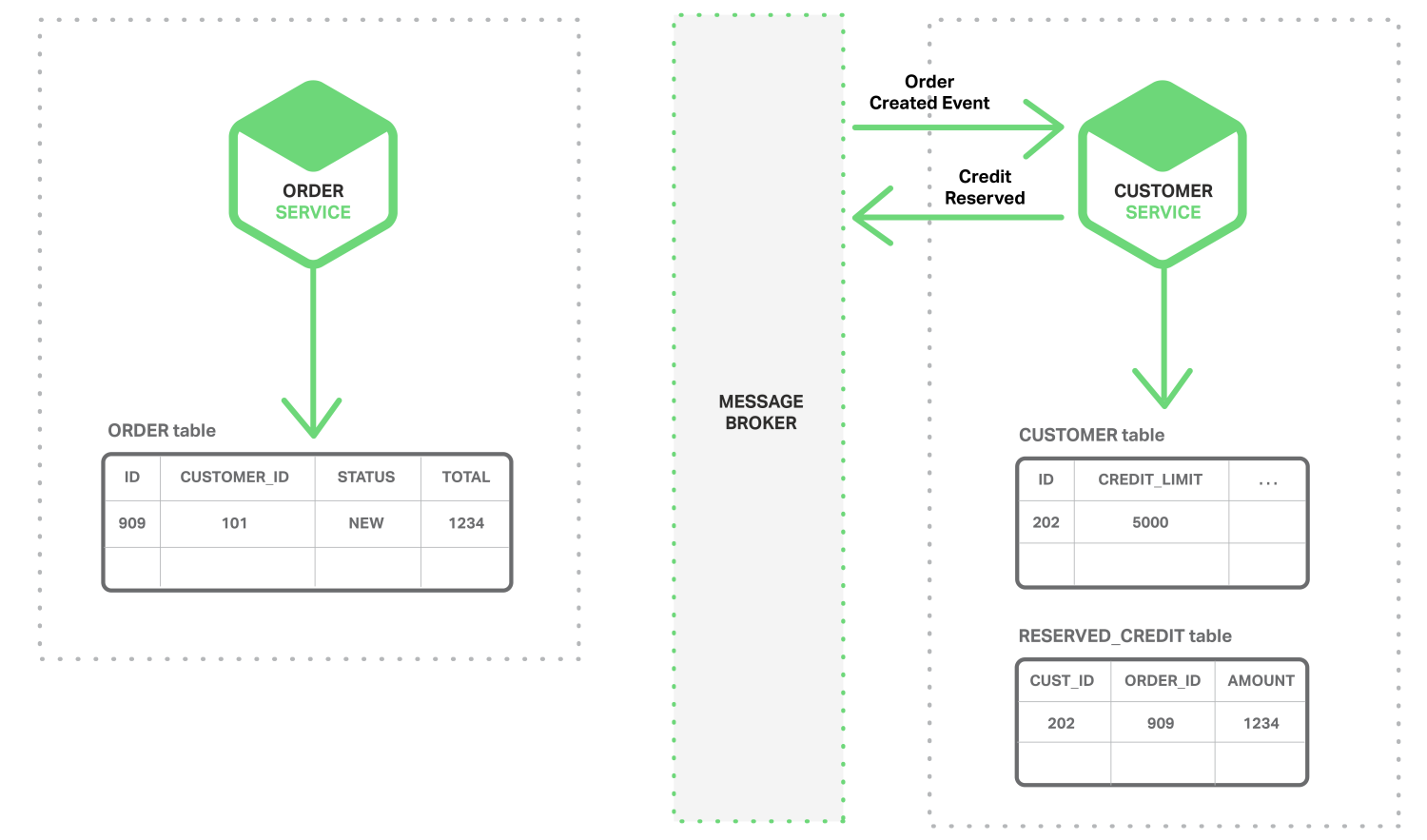
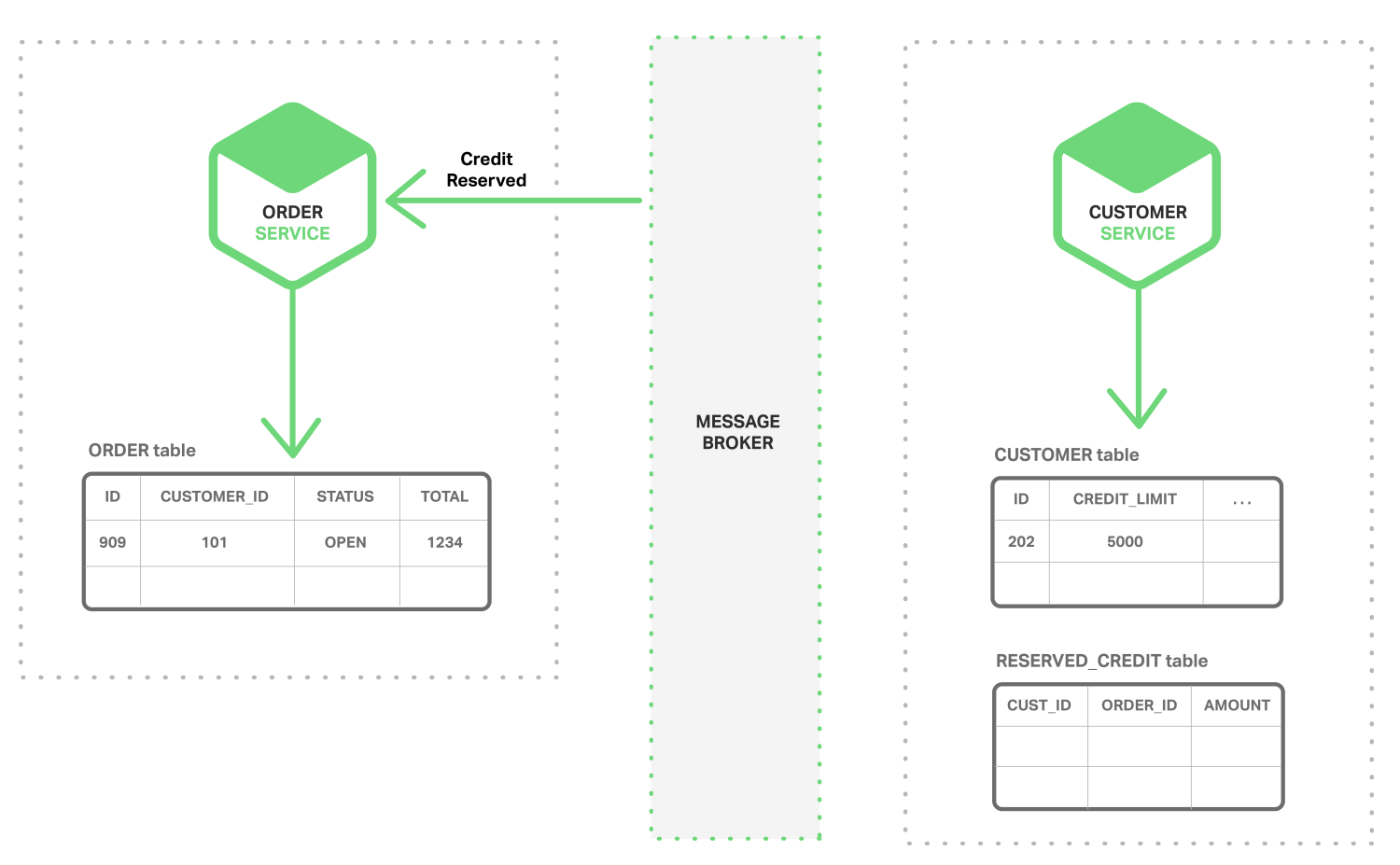
원자성을 달성하는 한가지 방법은 Application이 로컬 트랜잭션만을 포함하는 Multi-step process를 사용하여 이벤트를 게시하는 것이다. 트릭은 Business Entity의 상태를 저장하는 데이터베이스에 Message Queue로서의 기능을 갖는 EVENT 테이블을 가지는 것이다. Application은 (로컬) 데이터베이스 트랜잭션을 시작하고, Business Entity의 상태를 업데이트한다. 그리고 이벤트를 EVENT 테이블에 입력하고, 트랜잭션을 커밋한다. 별도로 분리된 Application이나 Process가 EVENT 테이블에 질의하여 Message Broker에 이벤트를 게시하고, 이벤트가 게시되었음을 표시하기 위해 로컬 트랜잭션을 사용한다. 다음 다이어그램은 디자인을 보여 준다.
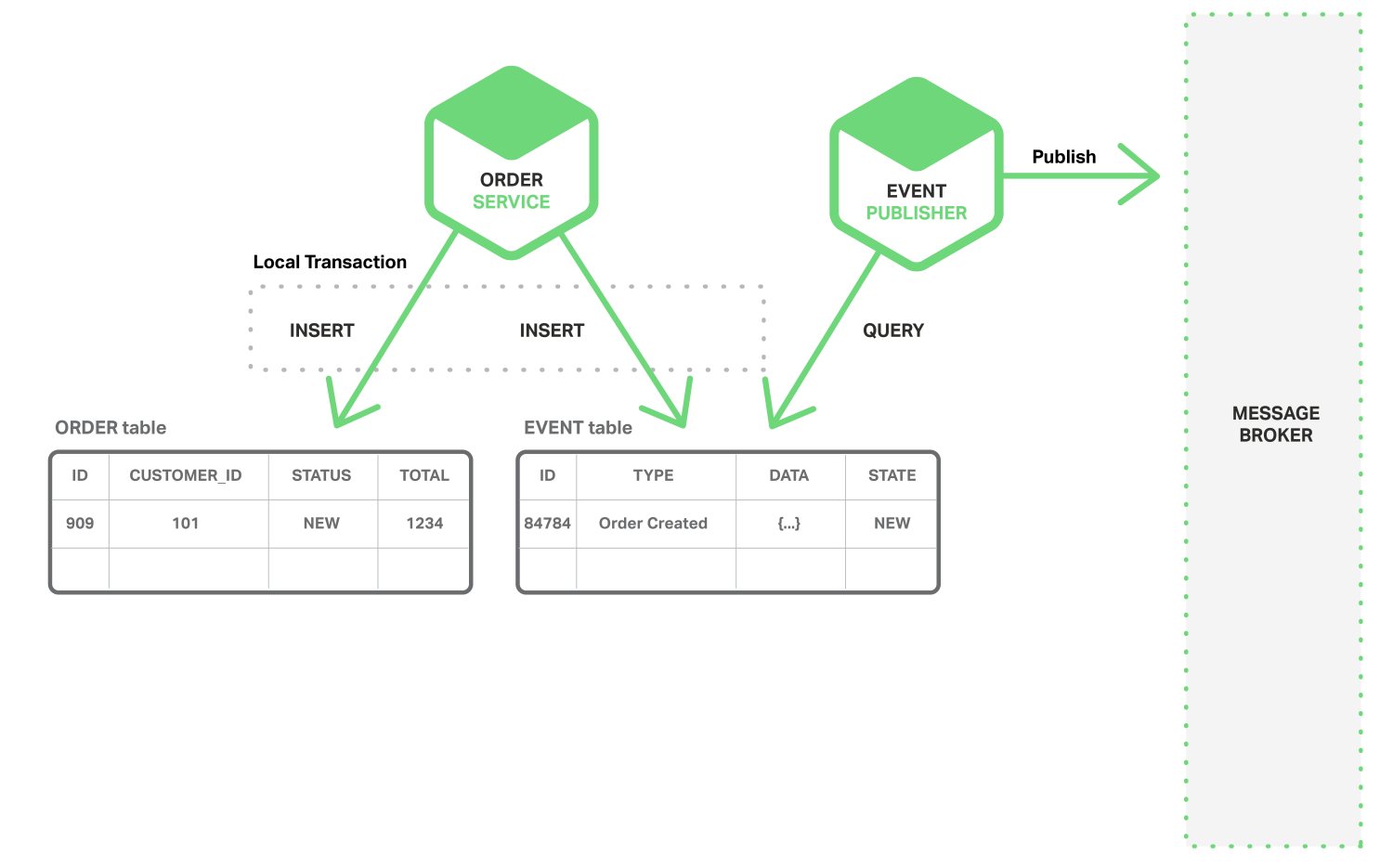
Order Service는 ORDER 테이블에 행을 삽입하고, EVENT 테이블에 Order Created 이벤트를 삽입한다. Event Publisher Thread나 Process는 게시되지 않은 이벤트에 대해 EVENT 테이블에 질의하고, 이벤트를 게시하고 나서 이벤트가 게시되었음을 표시하기 위해 EVENT 테이블을 업데이트한다.
이러한 접근 방법은 몇 가지 장점과 단점이 있다. 한가지 이점은 2PC에 의존하지 않고 각각의 업데이트에 대해 이벤트가 게시되는 것을 보장한다는 것이다. 또한, Application은 Business Level 이벤트를 게시하므로 추론할 필요가 없다. 이 접근법의 한가지 단점은 개발자가 이벤트 게시를 기억해야 하므로 잠재적으로 오류가 발생하기 쉽다. 이 접근법의 한계는 일부 NoSQL 데이터베이스를 사용하는 할 때, 제한된 트랜잭션과 쿼리 기능으로 인해 구현이 어렵다는 것이다.
이 접근법은 Application이 상태와 이벤트 게시를 업데이트 하기 위해 로컬 트랜잭션을 사용함으로써 2PC 필요성을 없애준다. 이제 Application이 간단히 상태를 업데이트하도록 함으로써 원자성을 달성하는 접근법에 대해 살펴보자.
Mining a Database Transaction Log
(데이터베이스 트랜잭션 로그 마이닝)
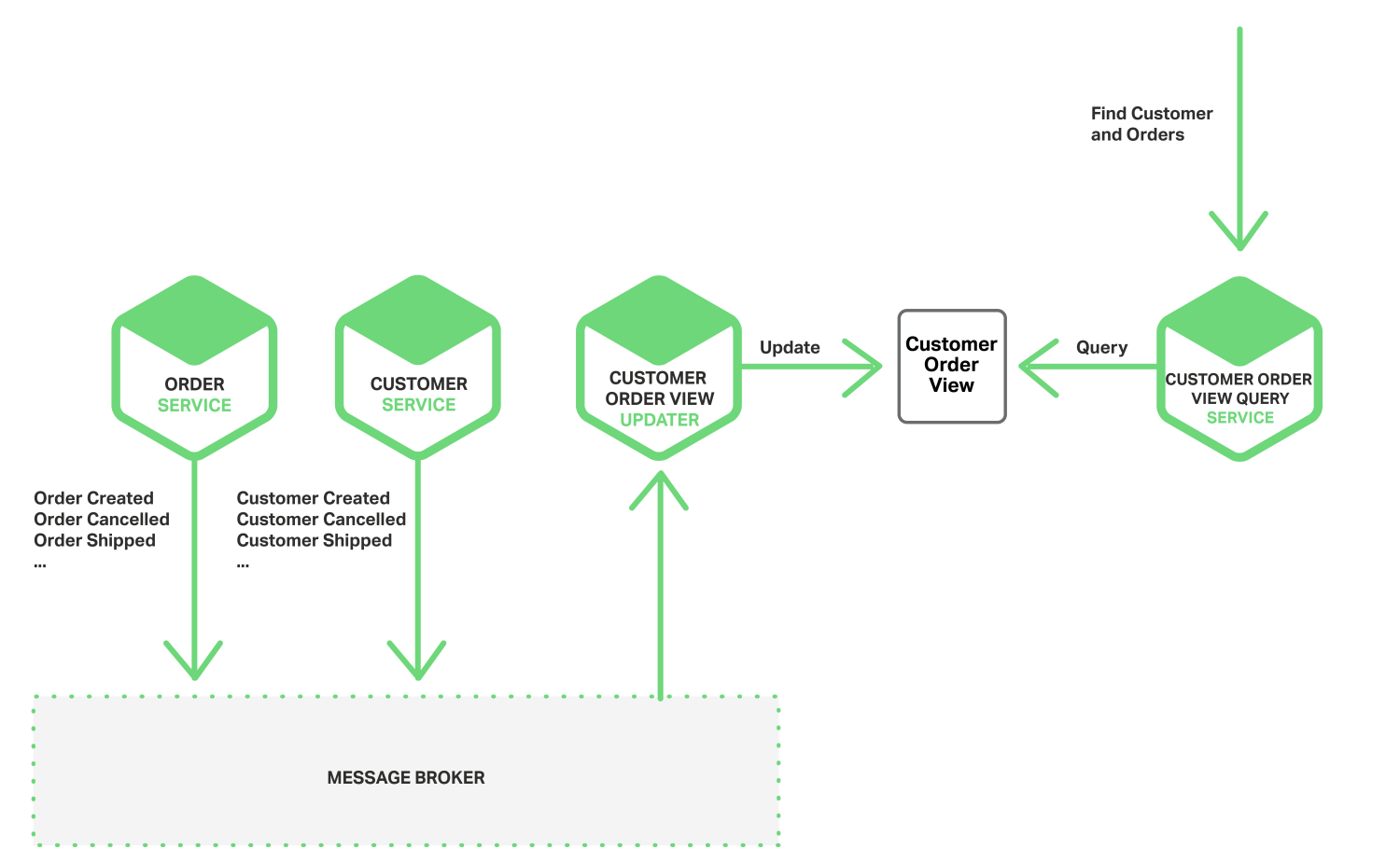
2PC없이 원자성을 달성하는 또다른 방법은 데이터베이스의 트랜잭션이나 커밋 로그를 조사하는 Thread나 Process에서 이벤트를 게시하는 것이다. Application은 데이터베이스를 업데이트 하고, 변경된 결과는 데이터베이스 트랜잭션 로그에 기록된다. Transaction Log Miner Thread나 Process가 트랜잭션 로그를 읽어서 Message Broker에 이벤트를 게시한다. 다음 다이어그램은 디자인을 보여준다.
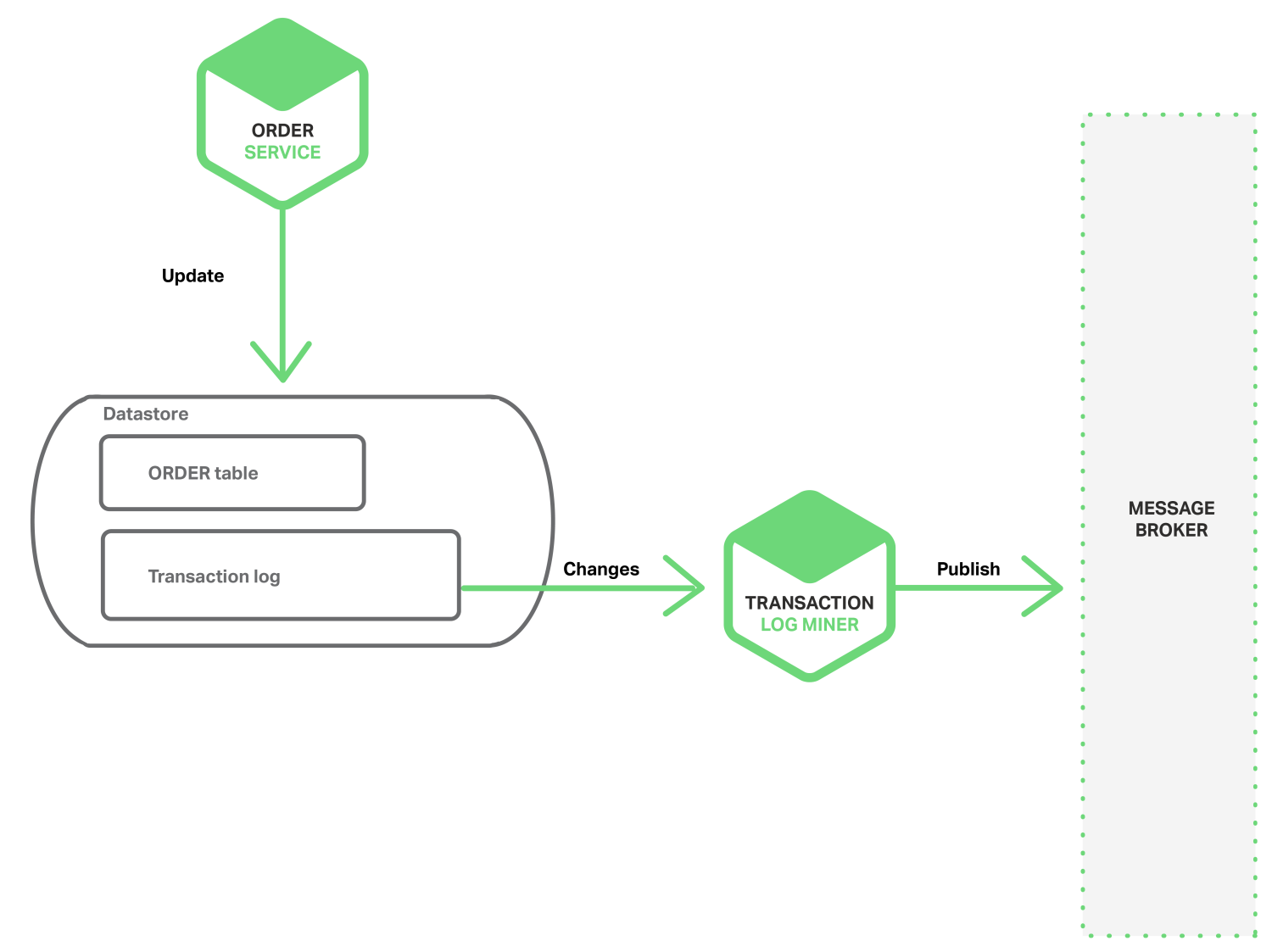
이러한 접근법의 한 예로, LinkedIn DataBus 오픈소스 프로젝트가 있다. DataBus는 Oracle의 트랜잭션 로그를 조사하고, 변화에 따른 이벤트를 게시한다. LinkedIn은 다양한 파생 데이터 저장소와 시스템의 기록이 일치하도록 하는데 DataBus를 사용한다.
또다른 예는 Managed NoSQL 데이터베이스인 AWS DynamoDB의 스트림 메커니즘이 있다. DynamoDB 스트림에는 지난 24시간동안 DynamoDB 테이블에서 아이템에 이루어진 변경 사항(생성, 변경, 삭제 작업)에 대한 수행 시간 순서가 포함되어 있다. Application은 스트림에서 이러한 변경 사항들을 읽을 수 있고, 예를 들어, 그 변경 사항들을 이벤트로 게시할 수 있다.
트랜잭션 로그 마이닝에는 여러 가지 장점과 단점이 있다. 한가지 장점은 2PC없이 각 업데이트에 대해 이벤트가 게시된다는 것이다. 트랜잭션 로그 마이닝은 또한 Application의 비즈니스 로직으로부터 이벤트 게시 부분을 분리함으로써 Application을 단순화 할 수도 있다. 주요 단점은 트랜잭션 로그의 형식이 각 데이터베이스에 따라 다르고, 심지어 데이터베이스 버전 간에 변경될 수도 있다는 것이다. 또한, 트랜잭션 로그에 기록되어 있는 low-level update에서 high-level business event를 리버스 엔지니어링하는 것이 어려울 수도 있다.
트랜잭션 로그 마이닝은 Application이 데이터베이스 업데이트 한가지만 하게 함으로써 2PC의 필요성을 없애준다. 그럼 이제 업데이트를 제거하고, 단지 이벤트에만 의존하는 다른 접근법에 대해서 살펴보자.
Using Event Sourcing
(이벤트 소싱 사용)
이벤트 소싱은 지속적인 비즈니스 엔터티에 근본적으로 다른, Event-Centric 접근방법을 사용하여 2PC없이 원자성을 달성한다. 엔터티의 현재 상태를 저장하는 대신, Application은 상태가 변화된 이벤트의 순서를 저장한다. Application은 이벤트를 재생함으로써 이벤트의 현재 상태를 재구성한다. 비즈니스 엔터티 상태가 변경될 때마다, 새로운 이벤트가 이벤트 리스트에 추가된다. 이벤트를 저장하는 것은 단일 작업이기 때문에 본질적으로 원자적이다.
이벤트 소싱이 어떻게 동작하는지를 보기 위해서 Order 엔터티를 예로 들어보라. 전통적인 접근방식에서는 각 주문은 ORDER 테이블의 행과 ORDER_LINE_ITEM 테이블의 행에 맵핑된다. 그러나, 이벤트 소싱을 사용할 때에는 Order Service는 상태 변경 이벤트 (Created, Approved, Shipped, Calcelled)의 형태로 Order를 저장한다. 각 이벤트는 Order의 상태를 재구성하는데 충분한 데이터를 포함하고 있다.
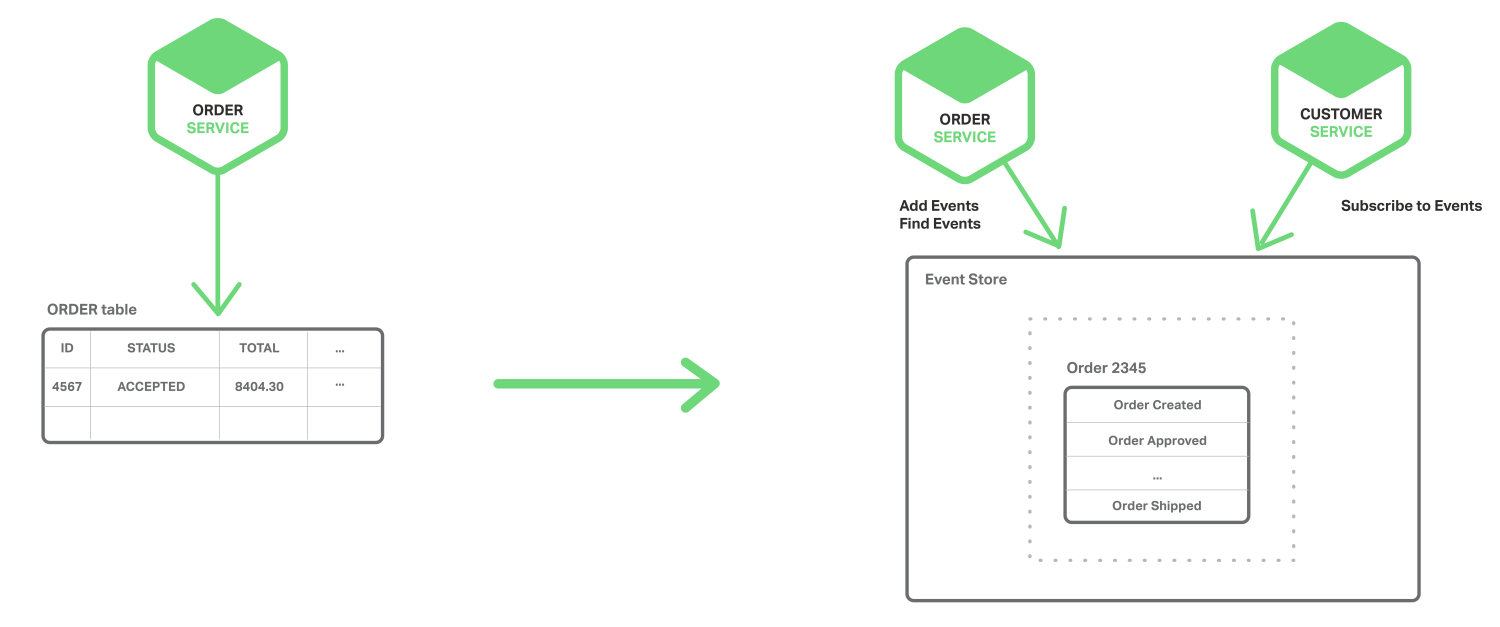
이벤트는 이벤트 데이터베이스인 Event Store에 지속적으로 저장된다. 저장소는 엔터티 이벤트들을 추가하고 검색할 수 있는 API를 가지고 있다. Event Store는 또한 이전에 설명한 아키텍처에서 Message Broker처럼 동작한다. Event Store는 서비스가 이벤트를 구독할 수 있도록 해주는 API를 제공한다. Event Store는 모든 관심있어하는 구독자들에게 모든 이벤트를 전달한다. Event Store는 Event-Driven Microservice Architecture의 백본(Backbone)이다.
Event Sourcing은 몇가지 장점을 가지고 있다. Event-Driven Architecture를 구현할 때, 주요 문제점들 중 하나를 해결하고 상태가 변경될 때마다 이벤트를 안정적으로 게시할 수 있다. 결과적으로, Microservice Architecture에서 데이터 일관성 문제를 해결한다. 또한, 도메인 객체가 아닌 이벤트를 지속적으로 저장하고 있기 때문에 객체-관계 임피던스(비율) 불일치 문제를 피할 수 있다. Event Sourcing은 또한 비즈니스 엔터티에 일어난 변경에 대해 100% 신뢰할 수 있는 감사 로그를 제공하고, 특정 시점의 엔터티 상태를 결정하는 임시적인 쿼리를 구현할 수 있다. Event Sourcing의 또다른 주요 장점은 비즈니스 로직이 이벤트를 교환하는 비즈니스 엔터티와 느슨하게 결합되어 있다는 것이다. 따라서, Monolithic Application을 Microservice Architecture로 쉽게 마이그레이션할 수 있다.
Event Sourcing은 몇가지 단점이 있다. 프로그래밍 스타일이 다르고, 익숙하지 않기 때문에 학습 곡선이 있다. 이벤트 저장소는 Primary Key(기본 키)로 비즈니스 엔터티를 직접 조회하는 경우만 지원한다. 쿼리를 구현하기 위해서는 Command Query Responsibility Segregation(CQRS:데이터를 변경하는 Command를 데이터를 읽어들이는 Query와 분리하는 아키텍처 패턴-CRUD중에서 Read와 실제 데이터를 변경하는 CUD를 분리하는 분산 환경에서 사용. 예를 들어 Read는 Cache를 사용하고, CUD가 일어나는 시점에 Cache를 업데이트 하는 방식이 이에 해당함)을 사용해야 한다. 따라서, Application은 결과적으로 일관된 데이터를 처리해야만 한다.


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/775