이것은 마이크로서비스로 어플리케이션을 작성하는 시리즈 중 다섯번째 Article이다. 첫번째 Article에서는 마이크로서비스 아키텍처 패턴을 소개하고, 마이크로서비스를 사용하는 것에 대한 장단점에 대해서 논의했다. 시리즈의 두번째와 세번째 Article에서는 마이크로서비스 내에서 다양한 측면의 통신에 대해서 설명했다. 네번째 Article에서는 서비스 검색과 밀접하게 관련된 문제에 대해서 살펴보았다. 이번 Article에서는 기어를 변속하여 마이크로서비스 아키텍처에서 떠오르는 Distributed Data Management(분산 데이터 관리)에 대해서 살펴보자.
Microservices and the Problem of Distributed Data Management
(마이크로서비스와 분산 데이터 관리 문제)
Monolithic 어플리케이션은 일반적으로 단일 관계형 데이터베이스(Single Relational Database)를 가지고 있다. 관계형 데이터베이스를 사용할 때의 주요 이점은 어플리케이션이 몇가지 중요한 점들을 보장하는 ACID 트랜잭션을 사용할 수 있다는 것이다.
- Atomicity(원자성) : 변경 사항들이 원자적으로 적용된다. (트랜잭션과 관련된 작업들이 부분적으로만 실행되고 중단되지 않는 것을 보장하는 능력. 즉, 중간 단계까지만 실행되고 나머지는 실패하는 일이 없도록 하는 것.)
- Consistency(일관성) : 데이터베이스의 상태는 항상 일관성이 있다. (트랜잭션을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스를 유지하는 능력.)
- Isolation(고립성) : 트랜잭션이 동시에 실행되는 경우라도, 순차적으로 실행된다. (트랜잭션 수행 시, 동시에 실행되더라도 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 능력.)
- Durability(지속성) : 한번 커밋된 트랜잭션은 실행취소 되지 않는다. (성공적으로 수행된 트랜잭션은 영원히 반영되어야 함.)
결과적으로 어플리케이션은 트랜잭션을 간단히 시작하고, 여러 행을 변경(삽입, 업데이트, 삭제)하고, 트랜잭션을 커밋할 수 있다.
관계형 데이터베이스를 사용하는 또 다른 큰 이점은 풍부하고, 선언적이며, 표준화된 Query Language인 SQL을 제공한다는 것이다. 여러 테이블에서 데이터를 결합하는 쿼리를 쉽게 작성할 수 있다. RDBMS Query Planner는 쿼리를 실행하기 위해 가장 적합한 방법을 결정한다. 어떻게 데이터베이스에 접근하는 지와 같은 저수준(low-level)의 세부 사항에 대해서 걱정할 필요 없다. 그리고 어플리케이션의 모든 데이터(어플리케이션이 필요로 하는 모든 데이터)가 하나의 데이터베이스에 있기 때문에 질의하기도 쉽다.
안타깝게도, 마이크로서비스 아키텍처로 전환하게 된다면 Data Access가 훨씬 더 복잡해진다. 그것은 각 마이크로서비스가 소유한 데이터가 개별 마이크로서비스 전용이고, API를 통해서만 접근할 수 있기 때문이다. 데이터를 캡슐화하는 것은 마이크로서비스가 서로 느슨하게 결합되고, 서로 독립적으로 진화하는 것을 보장한다. 만약 여러 서비스가 동일한 데이터에 접근한다면, 스키마 업데이트에는 시간이 오래 걸리고, 모든 서비스에 업데이트하기까지 조정이 필요하다.
설상가상으로, 다른 마이크로서비스는 종종 다른 종류의 데이터베이스를 사용한다. 최신 어플리케이션은 다양한 종류의 데이터를 저장 및 처리하고, 그에 따라 관계형 데이터베이스가 언제나 최고의 선택은 아니다. 어떤 Use Case에서는 특정 NoSQL 데이터베이스가 더 편리한 데이터 모델과 더 좋은 성능, 확장성을 가지고 있을 수 있다. 예를 들면, 텍스트를 저장하고, 질의하는 서비스는 ElasticSearch와 같은 텍스트 검색 엔진을 사용하는 것이 의미가 있다. 이와 유사하게, Social Graph 데이터를 저장하는 서비스는 Neo4j와 같은 Graph Database를 사용해야 한다. 결과적으로, 마이크로서비스 기반 어플리케이션은 종종 SQL과 NoSQL이 혼합된 형태, 소위 Polyglot Persistence(데이터를 저장할 때, 여러 가지 데이터 저장 기술을 사용하여 최고의 해결책을 찾는 것) 접근법을 사용한다.
데이터 스토리지에 대한 파티션된 Polyglot Persistence Architecture는 느슨하게 결합된 서비스와 더 좋은 성능, 확장성을 포함하여 많은 이점이 있다. 그러나, 일부 분산 데이터 관리 문제가 발생한다.
첫번째 문제는 여러 서비스간의 데이터 일관성을 유지하기 위해 비즈니스 트랜잭션을 어떻게 구현하는가이다. 왜 이것이 문제인지 알아보려면, 온라인 B2B Store 예제를 살펴보자. Customer Service는 신용 한도를 포함하여 고객 정보를 유지 관리한다. Order Service는 주문을 관리하고, 신규 주문이 고객의 신용 한도를 초과하지는 않는지를 검증해야 한다. Monolithic Application에서는 Order Service가 ACID 트랜잭션을 사용하여 간단히 사용 가능한 신용한도를 확인하고 주문을 생성할 수 있다.
반대로, 다음 다이어그램에서 보는 것처럼, 마이크로서비스 아키텍처에서는 ORDER와 CUSTOMER 테이블이 각각의 서비스 전용이다.
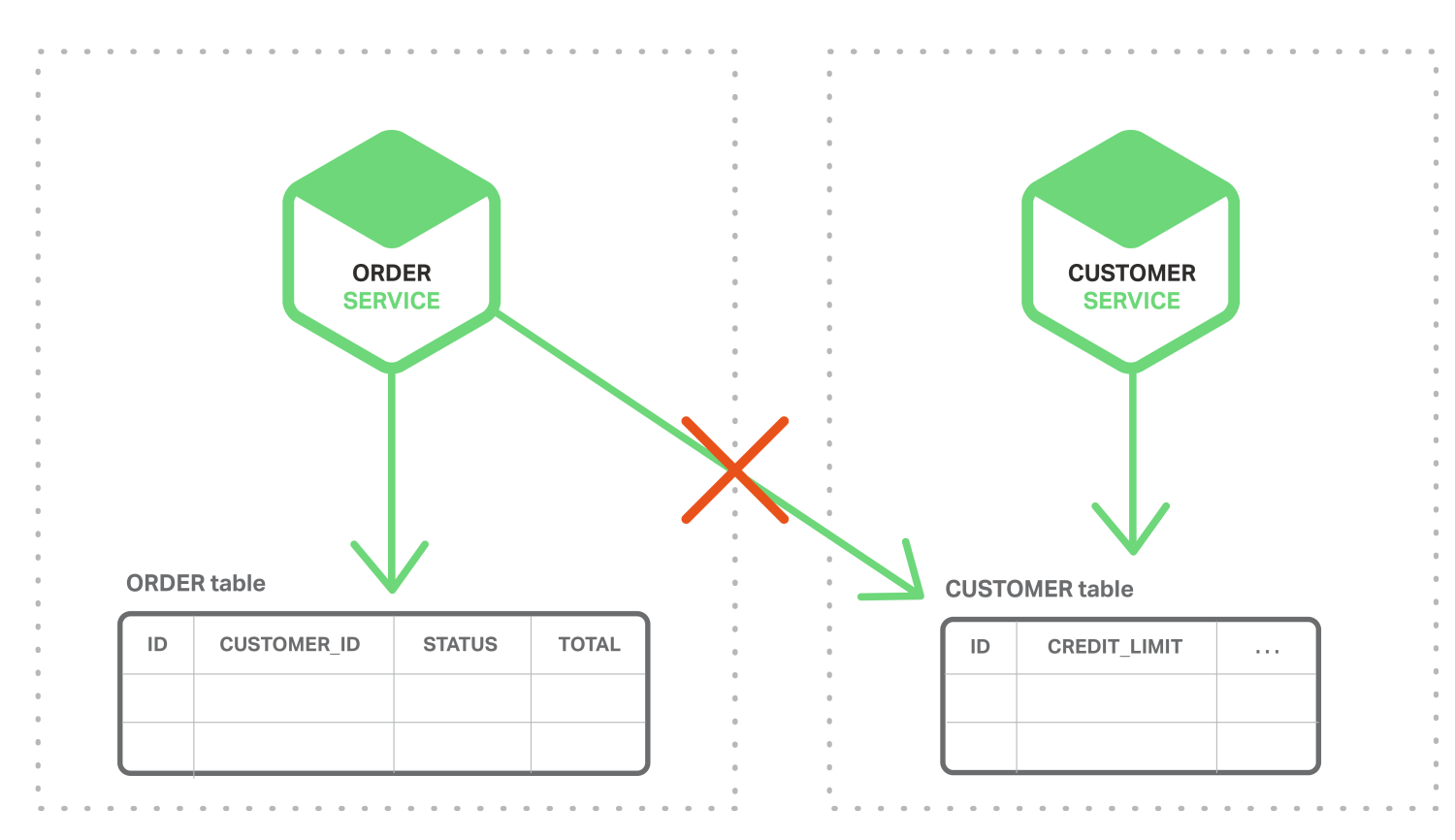
Order Service는 CUSTOMER 테이블에 직접적으로 접근이 불가능하다. Customer Service가 제공하는 API만 사용할 수 있다. Order Service는 잠재적으로 two-phase commit(2PC)라고 알려진 분산 트랜잭션을 사용해야만 한다. 그러나 2PC는 일반적으로 최근 어플리케이션에서 실행가능한 옵션이 아니다. CAP Theorem에서는 가용성과 ACID-Style의 일관성 중에서 선택할 필요가 있다. 그리고 가용성이 일반적으로 더 나은 선택이다. 더우기, 대부분의 NoSQL 데이터베이스와 같은 많은 현대 기술은 2PC를 지원하지 않는다. 서비스와 데이터베이스 간에 데이터 일관성을 유지하는 것이 필수적이기 때문에, 다른 솔루션이 필요하다.
두번째 문제는 여러 서비스에서 데이터를 조회하는 쿼리를 어떻게 구현하느냐이다. 예를 들면, 어플리케이션에서 고객과 고객의 최근 주문 내역을 표시하는 경우를 생각해 보자. Order Service는 고객의 주문 내역을 조회하는 API를 제공하고, 어플리케이션 측면의 Join을 사용하여 데이터를 조회할 수 있다. 어플리케이션은 Customer Service에서 고객을 조회하고, Order Service에서 고객의 주문 내역을 조회할 수 있다. 그러나, Order Service가 단지 Primary Key로 주문 내역을 조회할 수 있다고 가정해 보자.(아마도 단지 Primary Key기반 조회만 지원하는 NoSQL데이터베이스를 사용한다고 가정해 보자.) 이와 같은 상황에서는, 필요한 데이터를 조회하는 확실한 방법이 없다.


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/772