Strategy 3 – Extract Services
(세번째 전략 : 서비스 추출)
세번째 리팩토링 전략은 monolith 내 기존 모듈들을 독립형 마이크로서비스로 변환하는 것이다. 모듈을 추출하여 서비스로 변환할 때마다, monolith는 작아진다. 일단 충분히 모듈로 변환하고 나면, monolith는 문제가 되지 않을 것이다. Monolith는 완전히 사라지거나 또다른 서비스가 될 만큼 충분히 작아지게 된다.
Prioritizing Which Modules to Convert into Services
(서비스 변환 대상 모듈 우선 순위화)
크고 복잡한 monolithic 어플리케이션은 수십, 수백개의 모듈들로 이루어져 있다. 그리고 그 모듈들은 모두 추출 대상이다. 우선 변환할 모듈을 알아내는 것은 도전적인 일이다. 좋은 접근 방법은 쉽게 추출할 수 있는 몇 가지 모듈로 시작하는 것이다. 이것은 일반적으로 마이크로서비스와 특히 추출 프로세스에 대한 경험을 제공해 준다. 그 이후에, 가장 큰 이익을 주는 모듈들을 추출해야 한다.
모듈을 서비스로 변환하는 것은 일반적으로 시간이 많이 걸린다. 여러분은 얻을 수 있는 이익을 기반으로 모듈에 대한 순위를 매기기를 원한다. 일반적으로는 자주 변경되는 모듈을 추출하는 것이 유익하다. 한번 모듈을 서비스로 변환하고 나면, monolith와는 독립적으로 개발하고 배포할 수 있기 때문에 개발을 가속화하게 될 것이다.
Monolith의 나머지와 크게 다른 리소스 요구사항을 가지는 모듈을 추출하는 것도 유익하다. 예를 들면, 인메모리 데이터베이스를 가진 모듈을 서비스로 변환하고, 대용량 메모리를 가진 호스트에 배포할 수 있다. 이와 유사하게, 계산하기에는 비싼 알고리즘을 구현하는 모듈을 추출하는 것은 많은 CPU를 가진 호스트에 배포할 수 있기 때문에 가치가 있다. 특정 리소스 요구사항을 가진 모듈을 서비스로 변환함으로써, 어플리케이션을 훨씬 쉽게 확장할 수 있다.
어느 모듈을 추출할지를 알고 나면, 이미 존재하는 대략적인 경계(이음새로 알려진)를 찾는 것이 유용하다. 모듈을 서비스로 더 쉽고 값싸게 한다. 그러한 경계의 한 예로는 비동기 메시지를 통해 나머지 어플리케이션과 커뮤니케이션하는 모듈을 들 수 있다. 상대적으로 싸고 쉽게 모듈을 마이크로서비스로 변환할 수 있다.
How to Extract a Module
(어떻게 모듈을 추출하는가)
모듈을 추출하는 첫번째 단계는 모듈과 monolith 사이에 대략적인 인터페이스를 정의하는 것이다. Monolith는 서비스가 소유한 데이터를 필요로 하고, 그 반대의 경우도 마찬가지이기 때문에 대부분 양방향 API일 것이다. 모듈과 나머지 어플리케이션들 사이의 얽혀 있는 의존성과 잘 정리되어 있는 상호작용 패턴 때문에 양방향 API를 구현하는 것은 종종 어려운 일이다. Domain Model 패턴을 사용하여 구현된 비즈니스 로직은 도메인 모델 클래스 간의 수많은 연관성 때문에 리팩토링하기에 특히 어렵다. 이러한 의존성을 깨기 위하여 종종 중요한 코드를 변경해야만 할 필요가 있다. 다음 다이어그램은 리팩토링에 대해서 보여준다.
대략적인 인터페이스를 일단 구현하고 나면, 모듈을 독립적인 서비스로 변환할 수 있다. 이렇게 하기 위해서, monolith와 서비스가 Inter-Process Communication(IPC : 프로세스간 통신) 메커니즘을 사용하는 API를 통해 서로 통신할 수 있는 코드를 작성해야만 한다. 다음 다이어그램은 리팩토링 전, 도중, 후의 아키텍처를 보여준다.
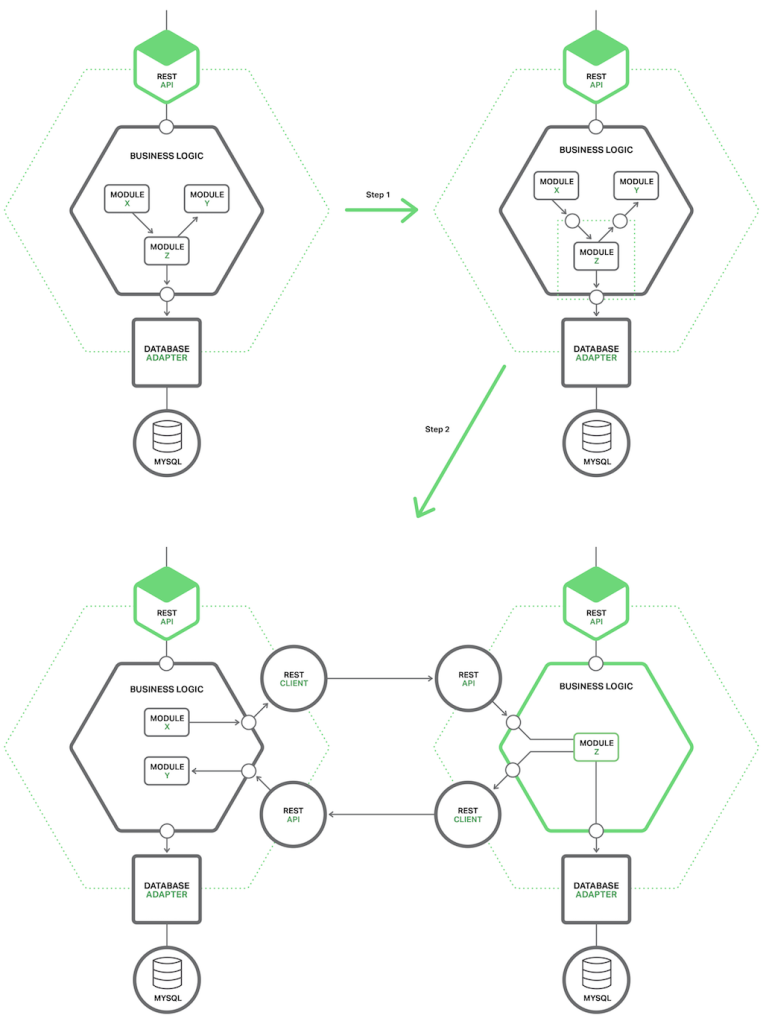
이 예제에서, 모듈 Z는 추출할 후보 모듈이다. 그 구성요소들은 모듈 X에서 사용되고, 모듈 Y를 사용한다. (즉, X 모듈에서는 Z 모듈의 구성요소를 사용하고, Z 모듈의 구성요소들은 Y 모듈을 사용한다.) 첫번째 리팩토링 단계는 대략적인 API 쌍을 정의하는 것이다. 첫번째 인터페이스는 모듈 Z를 호출하기 위해서 모듈 X에서 사용하는 인바운드 인터페이스이다. 두번째는 모듈 Y를 호출하기 위해 모듈 Z에서 사용하는 아웃바운드 인터페이스이다. (인바운드 : 모듈 Z의 입장에서 요청이 들어오는 방향, 아웃바운드 : 모듈 Z의 입장에서 요청이 나가는 방향)
리팩토링의 두번째 단계는 모듈을 독립적인 서비스로 변환하는 것이다. 인바운드, 아웃바운드 인터페이스는 IPC 메커니즘을 사용하는 코드로 구현된다. 서비스 검색과 같은 Cross-Cutting Concern(AOP에서 여러 비즈니스 로직에 공통으로 필요하여 별도 모듈로 쉽게 분리할 수 없는 요구사항. 예:보안, 로깅, 트랜잭션, 등)을 다루는 Microservice Chassis framework와 모듈 Z를 결합하여 서비스를 빌드할 필요가 있다.
일단 모듈을 추출하고 나면, monolith와 다른 서비스들과는 별도로 개발, 배포, 확장하 ㄹ수 있는 또다른 서비스를 가지게 된다. 서비스를 처음부터 재작성하게 될 수도 있다. 이 경우에는, 서비스와 monolith를 통합하는 API 코드가 2개의 도메인 모델 사이를 변환하는 Anti-Corruption Layer(반부패 계층)이 된다. 서비스를 추출하는 경우마다 마이크로서비스의 방향으로 또 한 걸음 나아가는 것이다. 시간이 지날수록 monolith는 작아지고, 마이크로서비스는 늘어날 것이다.
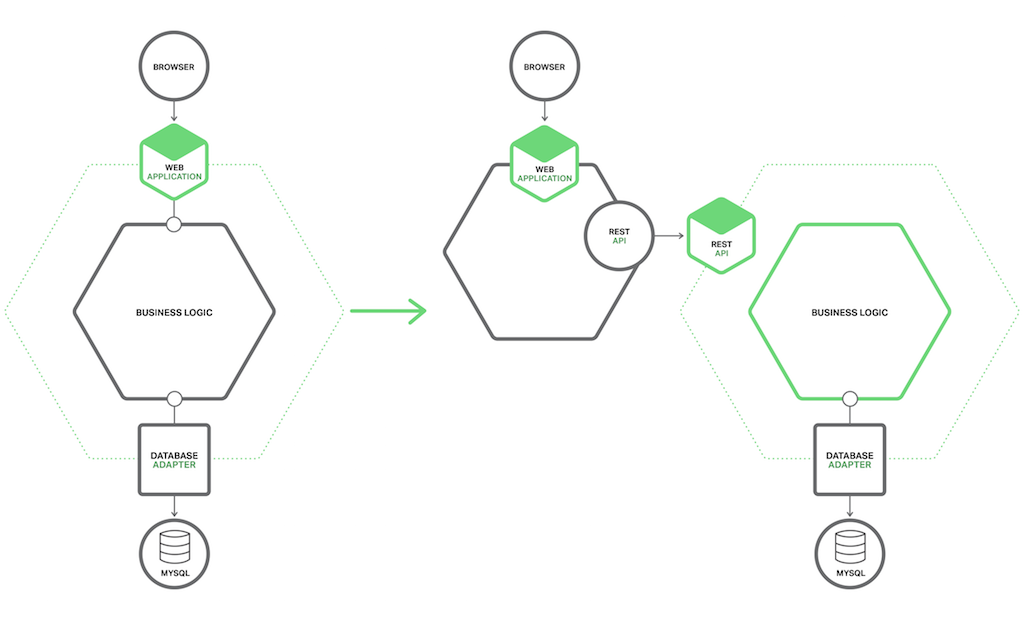

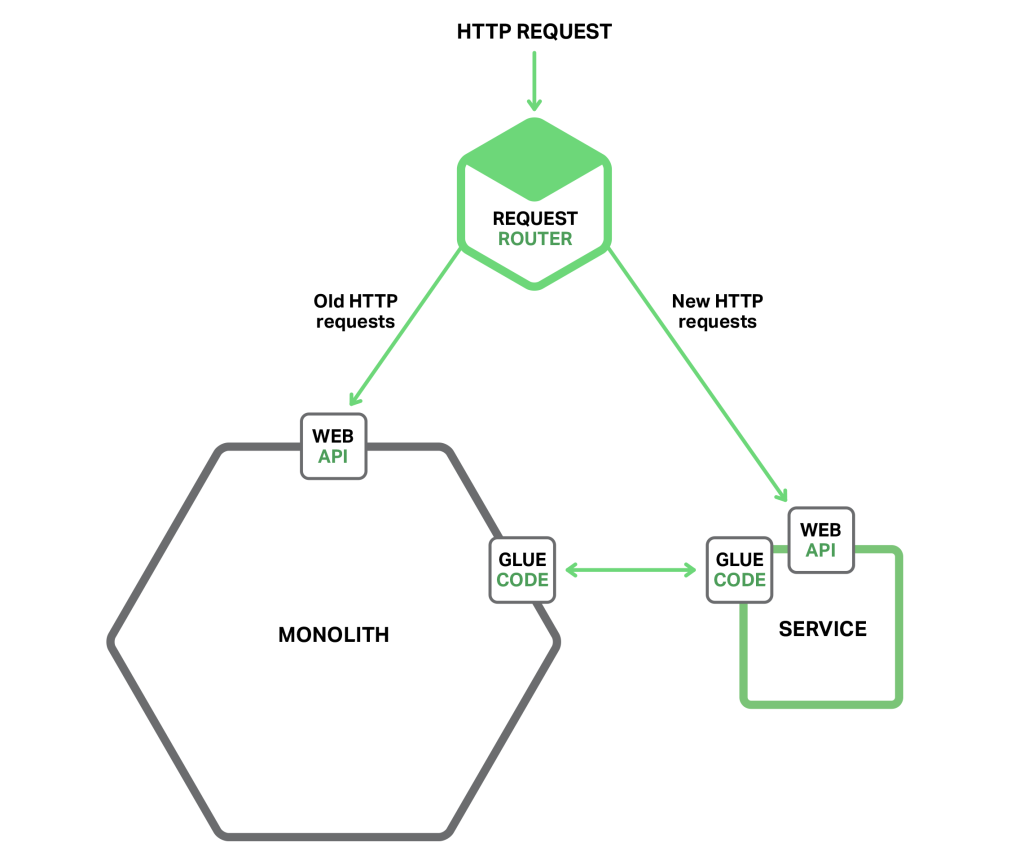


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/784