Isolating the Domain: Introducing the Applications
도메인의 책임이 시스템의 다른 부분과 뒤섞이는 것을 방지하기 위해서, 도메인 레이어를 표시하는 Layered Architecture를 적용해 보자.
깊은 분석 없이도, 3가지 user-level application function을 명시할 수 있고, 3개의 어플리케이션 레이어 클래스에 할당할 수 있다.
1. 특정 화물(Cargo)에 대한 과거와 현재 처리에 접근할 수 있는 Track query.
2. 시스템에 New Cargo를 등록하고 준비할 수 있는 Booking Application.
3. 각 화물(Cargo)의 처리를 기록할 수 있는 Incident Logging Application. (Tracking Query에서 검색한 정보를 제공)
Distinguishing ENTITIES and VALUE Objects
(Entity와 Value Object의 구분)
Customer
Customer는 명백하게 사용자를 나타내는 Indentity를 가지고 있으므로 모델에서 Entity이다.
Cargo
2개의 동일한 상자가 구분되어야 하기 때문에 Cargo 객체는 Entity이다. 실제로 화물 회사에서는 각 화물에 tracking ID를 부여한다.
이러한 ID는 자동으로 생성되어 user에서 보여지고, 이 경우에는 booking time(화물을 부칠 때)시 customer에게 전달 될 것이다.
Handling Event and Carrier Movement
무슨 일이 일어나고 있는지 추적하기 위해서 개별 incident에 주의를 기울인다.
실제 세상의 이벤트를 반영하고, 일반적으로 교환가능하지 않다. 따라서 Entity에 해당한다. 개별 Carrier Movement는 수화물 선적 스케쥴에서 얻은 코드로 명시될 수 있다.
Handling Events는 Cargo ID, Completion Time, Type의 조합으로 유일하게 명시될 수 있다. 왜냐하면, Same Cargo는 동시에 선적되고, 하선될 수 없기 때문이다.
Location
동일한 이름을 가진 2개의 장소는 동일한 장소가 아니다. 위도와 경도가 유일한 키로 제공될 수 있지만, 실용적이지 않기 때문에 이 시스템에서 대부분의 목적에 적합한 측정값이 아니다. Location은 수화물 선적 항로와 다른 도메인 특화 개념에 따른 장소와 관련되어 있는 지정학적 모델의 일부이다. 따라서 임의의, 내부적인, 자동으로 생성된 identifier가 제공될 것이다.
Delivery History
까다로운 항목이다. Delivery History는 교환가능하지 않기 때문에 Entity이다. 그러나 Delivery History는 Cargo와 1:1 관계성을 갖기 때문에 실제로는 그 자체로 identity를 가지지 않는다. Delivery History의 identity는 Cargo의 것을 빌려온다. 모델을 Aggregate로 할 때 더 분명해진다.
Delivery Specification
비록 Delivery Specification이 Cargo의 목적지를 의미하지만, 이 추상화는 Cargo에 달려 있다. Delivery Specification은 사실은 어떤 Delivery History의 가상의 상태를 표현한다. Cargo에 첨부된 Dilivery History가 점차적으로 Cargo에 추가된 Delivery Specification을 만족시킬 것으로 기대한다. 만약 동일한 장소에 2개의 Cargo를 가지고 있다면, 동일한 Delivery Specification을 공유하지만, 동일한(empty)로 히스토리로 시작하는 경우일지라도, 동일한 Delivery History를 공유하는 것은 아니다. Delivery Specification은 Value Object이다.
Role and Other Attributes
Role은 자격을 얻는 연관성(association)에 대해서 이야기하고 있지만, 히스토리나 연속성은 없다. Role은 Value Object이고, 다른 Cargo/Customer 연관성 사이에 공유할 수 있다. 타임스탬프나 이름과 같은 다른 속성은 Value Object이다.
Designing Associations in the Shipping Domain
Original Diagram에 있는 연관성 중에 어느 것도 지정된 횡방향이 없지만, 설계에서 양방향 연관성은 문제가 있다. 또한 횡방향은 종종 도메인에 대한 통찰력(insight)을 포착하여 모델 그 자체를 심화시킨다.
Customer가 선적된 모든 Cargo에 대해 직접적인 참조를 가지고 있는 경우에는, 장기간 반복되는 Customer이 성가셔 할 것이다. 또한 Customer의 개념은 Cargo에 특화된 것이 아니다. 커다란 시스템에서는, Customer가 많은 객체로 작업하는 역할을 가지게 될 것이다. 그러한 특정 책임에 대한 자유를 주는 것이 가장 좋은 방법이다. Customer가 Cargo를 발견하는 능력을 필요로 하는 경우, 데이터베이스 쿼리를 통해서 작업할 수 있다.
어플리케이션이 선박의 재고(inventory)를 추적하는 경우에는 Carrier Movement에서 Handling Event로의 이동이 중요하다. 하지만, 비즈니스에서는 단지 Cargo가 필요할 뿐이다. Handling Event에서 Carrier Movement로 연관성을 이동가능하게 하는 것은 비즈니스에 대한 이해를 획득하는 것이다. 다중성을 가진 방향성을 허용하지 않기 때문에 단순한 객체 참조로 구현을 줄일 수 있다.
AGGREGATE Boundaries
Customer, Location, Carrier Movement는 고유한 Identity를 가지고, 많은 Cargoes에서 공유하기 때문에 자신의 속성과 여기서 논의하는 상세 레벨(detail level) 아래에 있을 수 있는 다른 객체들을 포함하는 자체 Aggregate의 root가 되어야만 한다.
Cargo는 또한 분명한 Aggregate root이지만, boundary를 그릴 때에는 약간 생각이 필요하다.
Cargo Aggregate는 존재하지 않는 모든 것을 쓸어 담을 수 있지만, 특정 Cargo에는 Delivery History와 Delivery Specification, Handling Event를 포함할 수 있다. Delivery History는 Cargo ID를 통해서 조회될 수 있으므로, Cargo Boundary내부에 존재하는 것이 적합하다. Delivery Specification(배송 명세서)은 Value Object이므로 Cargo Aggregate내에 포함되는 것에 문제가 안 된다.
Handling Event는 또다른 문제이다. 앞에서 이것을 검색할 수 있는 2가지 데이터베이스 쿼리에 대해서 고려했다. 하나는 Cargo Aggregate내에 오컬이 되는 Collection에 대한 가능한 대안으로써 Delivery History에 대해 Handling Event를 찾는 것이다. 다른 하나는 특정 Carrier Movement에 대해 로드(load)하고 준비할 모든 동작을 찾도록 사용하는 것이다. 두번째 경우에, Cargo를 처리하는 활동은 Cargo 그 자체와 별개로 고려될 때도 의미가 있어 보인다. 따라서 Handling Event는 그 자체로 Aggregate의 Root가 되어야 한다.
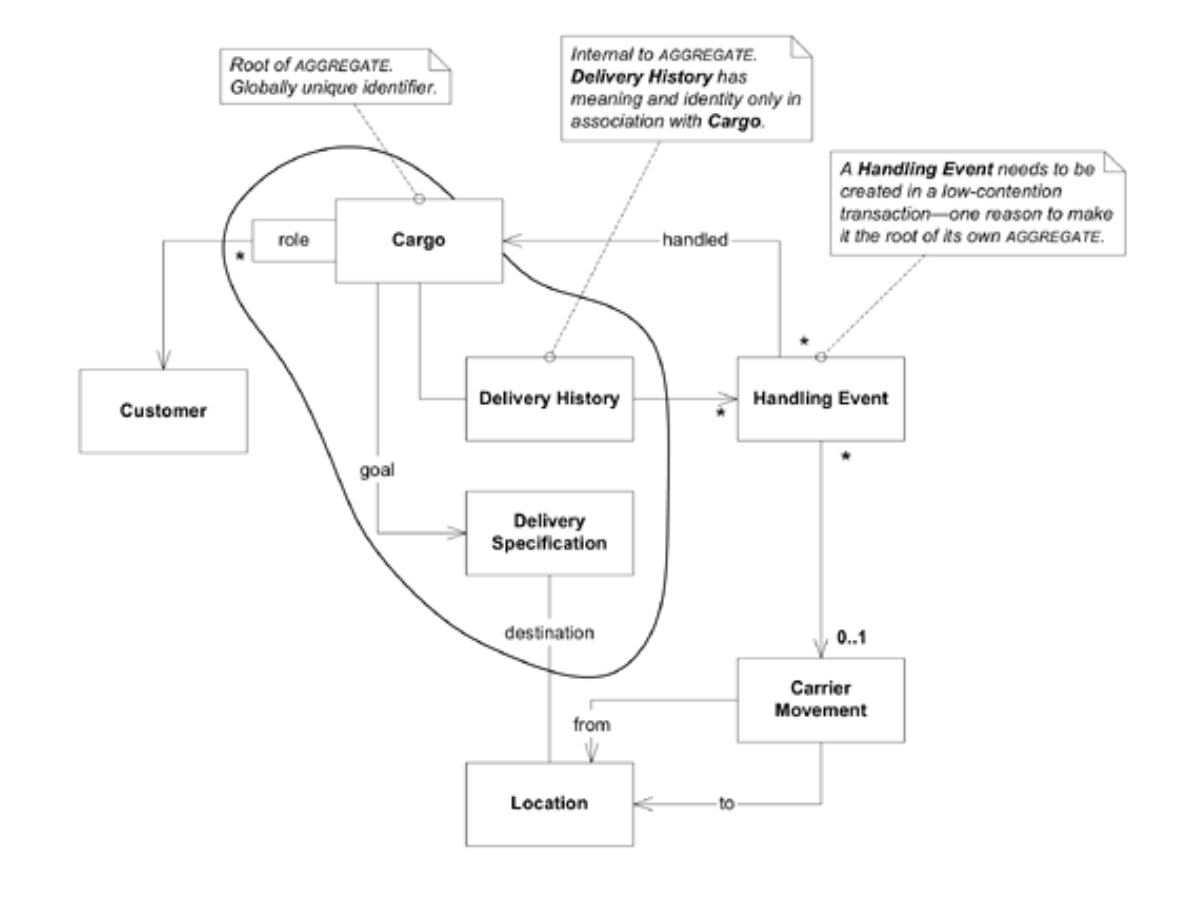
[그림 7-1] Aggregate Boundary
Selecting REPOSITORIES
설계에는 Aggreate root가 5개 Entity로 존재한다. 따라서 Repository를 가질 수 있도록 허용된 다른 객체가 없기 때문에 고려 대상을 제한할 수 있다.
실제로 이러한 Entity들 중에서 어느 것이 Repository를 가져야 하는지 결정하기 위해서는, 어플리케이션 요구사항으로 돌아가야만 한다. 예약 어플리케이션(Booking application)을 통해서 예약하기 위해서 사용자는 여러 역할을 수행할(수화물 배송자(shipper), 수화물 수취인(receiver), 등) Customer(s)를 선택해야 한다. 따라서 Customer Repository가 필요하다. Cargo에 대한 목적지를 명시하기 위해서 Location을 찾을 수 있는 Location Repository를 생성해야 한다.
Activity Logging Application은 사용자가 Cargo가 적재되고 있는 Carrier Movement를 찾을 수 있어야 하므로 Carrier Movement Repository가 필요하다. 사용자는 Cargo가 어느 시스템에 로드되었는지 알려야 하므로 Cargo Repository도 필요하다.
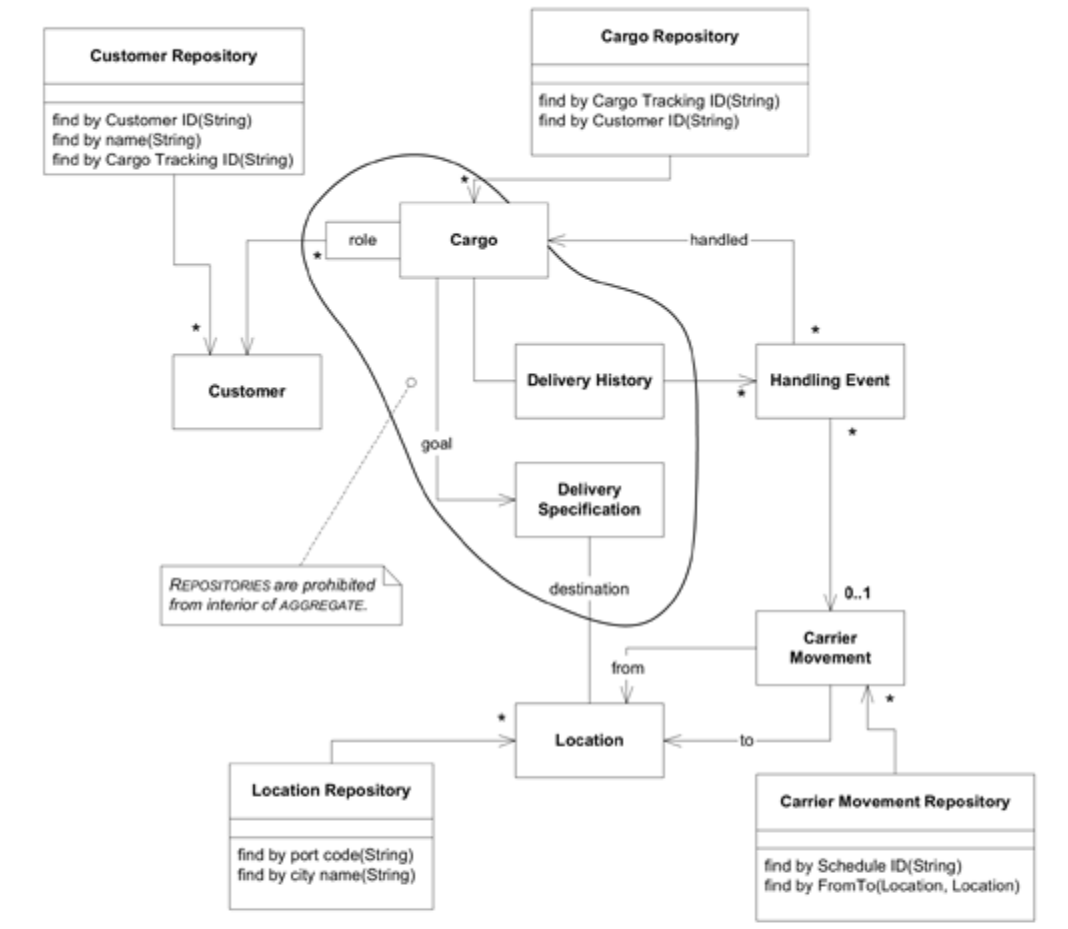
[그림 7-2] Repository
여기서 첫번째 iteration에서 Delivery History와의 연관성을 Collection으로 구현하기로 결정했고, Carrier Movenent로 무엇이 로드되었는지를 찾을 필요가 없기 때문에 Handling Event Repository는 없다. 이러한 이유중 하나가 만약에 바뀐다면, Repository를 추가해야 한다.
Walking Through Scenarios
이러한 모든 결정을 상호 체크하기 위해서 지속적으로 어플리케이션 문제를 효율적으로 해결할 수 있는 시나리오를 통해 단계를 밟아야 한다.
Sample Application Feature: Changing the Destination of a Cargo
경우에 따라서 Customer는 "화물을 Haceksack로 보내달라고 했지만, 사실은 Hoboken으로 보내야 합니다"라고 말할 수 있는데, 시스템에서는 이러한 변경을 반영할 수 있어야 한다.
Delivery Specification은 Value Object이기 때문에, 간단히 버리고 새로운 것을 얻을 수 있다. 따라서, Cargo는 setter method를 통해서 변경할 수 있다.
사용자는 동일한 Customer의 반복되는 예약은 유사한 경향이 있기 때문에 이전 Cargo를 새로운 것에 대한 프로토타입으로 사용하고 싶어 한다. 어플리케이션은 Repository에서 Cargo를 찾은 다음, 선택된 것을 기반으로 새로운 Cargo를 생성하는 명령을 선택할 수 있을 것이다. Prototype 패턴을 사용하여 설계할 것이다.
Cargo는 Eentity이고, Aggregate의 Root이다. 그러므로, 주의 깊게 복사해야 한다. Aggregate Boundary에 둘러싸여 있는 각 객체나 속성에 무슨 일이 일어날지 고려해야 한다.
각각에 대해서 살펴보자.
Delivery History: 이전 History가 적용되지 않기 때문에 새로운 비어있는 객체를 생성해야 한다. Aggregate Boundary내에 Entity가 있는 일반적인 경우에 해당한다.
Customer Roles: 새로운 수화물(shipment)에서 동일한 역할을 수행하게 될 수 있으므로, 키를 포함하고 있는 Customer를 참조하는 키를 가지고 있는 맵(Map, or Collection)을 복사해야 한다. 하지만, Customer 객체 자체를 복사하지 않도록 주의해야 한다. Aggregate Boundary 밖에 있는 Entity이기 때문에, 이전에 참조된 Cargo 객체와 동일한 Customer 객체에 대한 참조로 끝나야 한다.
Tracking ID: 처음부터 새로운 Cargo를 생성할 때처럼 동일한 소스에서 새로운 Tracking ID를 제공해야 한다.
모두 Cargo Aggregate Boundary 내부에서 모든 것을 복사했음에 유의하라. 복사본에 약간의 수정이 있을 수 있지만, Aggregate Boundary 바깥에는 전혀 영향을 미치지 않는다.
Object Creation
FACTORIES and Constructors for Cargo
Cargo에 대한 멋진 Factory를 가지고 있거나 "Repeat Business"시나리오에서처럼 Factory로 또다른 Cargo를 사용한다면, 여전히 Primitive 생성자를 가져야 한다.
생성자가 불변성(invariant)을 만족시키거나 최소한 Entity의 경우, Identity를 손대지 않는 객체를 생성하기를 원한다.
Factory에서 리턴하는 결과는 동일할 것이다. 비어 있는 Delivery History, 널 값을 가지는 Delivery Specfication을 가진 Cargo를 리턴한다.
Pause for Refactoring: An Alternative Design of the Cargo AGGREGATE
모델링과 설계는 지속적인 전진 과정이 아니다. 모델과 설계를 개선하는 새로운 통찰력(insight)을 얻기 위해서 잦은 리팩토링이 없으면 서서히 멈출 것이다. 비록 작업을 수행하고, 모델을 반영할지라도 지금까지, 이 설계에 몇 가지 까다로운 측면이 있다. 설계 시작할 때 중요하지 않게 보이는 문제들은 성가신 문제가 되기 시작할 것이다.
만약 동시에 몇몇 사용자가 Cargo를 수정하는 경우, Handling Event 트랜잭션은 실패하거나 지연될 것이다. Handling Event를 입력하는 것은 빠르고 쉽게 해야 하는 작업 활동(operational activity)이므로, 중요한 어플리케이션 요구사항은 경합없이 Handling Event를 입력할 수 있는 기능이다. 이것은 다른 설계를 고려하게 한다.
Handling Event의 Delivery History Collection을 쿼리로 대체하면 Aggregate 밖에서 무결성 이슈를 제기하지 않고 Handling Event를 추가할 수 있다.
이러한 변경은 간섭없이 트랜잭션을 완료할 수 있게 한다. 만약 입력되는 Handling Event가 많고, 상대적으로 쿼리수가 적으면, 이 설계는 더 효율적이 된다. 사실, 관계형 데이터베이스가 기본 기술일 경우, 쿼리를 사용하여 Collection을 에뮬레이션할 수 있다.
Collection보다 쿼리를 사용하는 것이 Cargo와 Handling Event 사이에 주기적 참조에 대해 일관성을 유지하는데 대한 어려움을 감소시킨다. 쿼리에 대한 책임을 지기 위해서 Handling Event에 대한 Repository를 추가한다.
Handling Event Repository는 특정 Cargo와 관련된 Event에 대한 쿼리를 지원한다. 게다가, Repository는 특정 질문에 대해 효율적으로 대답하기 위해 최적화된 쿼리를 제공할 수 있다. 예를 들면, 잦은 접근 경로가 마지막으로 보고된 로드 혹은 언로드를 찾는 Delivery History라면, Cargo의 현재 상태를 추론하기 위해서 관련된 Handling Event만을 리턴하도록 쿼리를 고안할 수 있다.
특정 Carrier Movement에 로드된 모든 Cargo를 찾는 쿼리를 원한다면, 쉽게 추가할 수 있다.


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/826