RDD는 다음 2가지 형태의 Operation을 지원한다.
Transformation은 map,
filter와 같은 새로운 RDD를 return하는 RDD상의 operation이다. Action은 driver program으로 결과를 return하거나 storage에 결과를 write하고, count나 first와 같은 연산을 시작하는 operation이다. Spark에서는
transformation과 action을 아주 다르게 취급한다. 따라서, 여러분이 수행하고자 하는 작업의 형태에 대해서 이해하는 것이 아주 중요하다. 만약 여러분이 여전히 주어진 기능에 대해서 transformation인지, action인지 혼란스럽다면 return 타입을 통해 알 수 있다. Transformation은 새로운 RDD를 return하지만, action은 다른 data type을 return한다.
Transformations
Transformation은 새로운 RDD를 return하는 operation이다. Lazy evaluation section에서 논의되겠지만, transformed
RDD는 단지 여러분이 action에서 사용할 때, 느긋하게(lazily) 계산된다. 많은 transformation(변형)이 element측면에서 일어난다. Transformation은 한번에 하나의 element상에서 동작하지만, 모든 transformation이 그런 것은 아니다.
예를 들면, 수많은 메시지를 담고 있는 log.txt라는 로그 파일을 가지고 있다고 생각해보자. 그리고 그 중에서 error 메시지만을 추출하고 싶다. 여기에 앞에서 보았던 filter
transformation을 사용할 수 있다. Spark의 3가지 언어로 filter API를 살펴보면 다음과 같다.
Example 3-8. Python filter example
inputRDD = sc.textFile("log.txt")
errorsRDD = inputRDD.filter(lambda x:"error" in x)
Example 3-9. Scala filter example
var inputRDD = sc.textFile("log.txt")
var errorsRDD = inputRDD.filter(line =>
line.contains("error"))
Example 3-10. Java filter example
JavaRDD<String> inputRDD = sc.textFile("log.txt");
JavaRDD<String> errorsRDD = inputRDD.filter(
new Function<String,
Boolean>() {
public Boolean call
(String x) {return x.contains("error");}
}
);
Filter operation은 기존의 inputRDD에 대한 돌연변이가 아님에 주의하라. 전혀 새로운 RDD에 대한 포인터를 return한다. inputRDD는 프로그램내에서-예를 들어, 다른 단어들을 검색하는데-나중에 재사용할 수 있다. Warning이라는 단어를 검색하는데 inputRDD를 사용해보자. 그 때, 새로운 transformation인 union을 사용하여 error나 warning 단어를 포함하고 있는 모든 line을 출력할 수 있다. 이에 대한 Python code가 있지만, union() function은 3가지 언어에서 모두 동일하다.
Example 3-11. Python union example
errorsRDD = inputRDD.filter(lambda x:"error" in x)
warningsRDD = inputRDD.filter(lambda x:"warning" in x)
badLinesRDD = errorsRDD.union(warningsRDD)
union은 filter와는 약간 다르다. 하나의 RDD가 아니라 2개의 RDD를 가지고 동작하기 때문이다. Transformation은 복수 개의 input RDD를 가지고 동작할 수 있다.
끝으로, transformation을 사용하여 서로 다른 새로운 RDD를 이끌어낼 때, Spark는 다른 RDD 사이의 dependency 집합을 추적하고 유지한다. 그것을 lineage graph라고 한다. Spark는 요구에 맞춰 각 RDD를 계산할 때, 이 정보를 이용하고 Persistent RDD의 일부 정보가 유실되었을 때, 이를 이용해 복구한다.
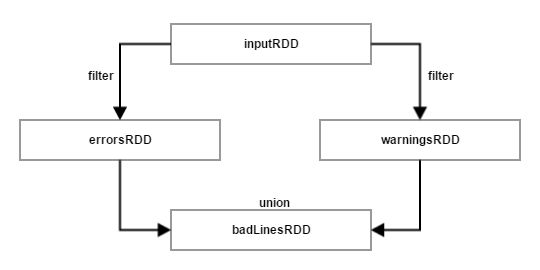
<Figure 3-1. RDD lineage graph created during log analysis>
트랙백 주소 :: http://www.yongbi.net/trackback/681
트랙백 RSS :: http://www.yongbi.net/rss/trackback/681


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/683