많은 IT조직들은 비록 관련은 있지만, 통합되지 않은 Hadoop에 저장되어 있는 엄청난 볼륨의 소형, 중형, 대형 데이터 세트에 압도당합니다. 그러나 통합된 데이터 관리 프레임워크를 올바르게 사용하면, Data Lake를 통해서 조직들은 통찰력을 얻고 데이터 세트간의 연관 관계를 발견할 수 있습니다.
통합 데이터 관리 프레임워크 기반 Data Lake는 전통적인 EDW에서 필요한 비용이 많이 들고 번거로운 ETL 데이터 준비 프로세스를 제거해 줍니다. 데이터는 Data Lake로 원활히 유입되고, 비즈니스 사용자가 필요로 할 때, 정보의 위치를 찾고 연결하는데 도움이 되는 메타데이터 태그로 관리됩니다. 이러한 접근 방법을 통해서 분석가는 매 단계마다 IT를 관련시키지 않고 IT 리소스를 보존하면서 데이터에서 중요한 가치를 창출하는 중요한 업무를 자유롭게 수행할 수 있습니다.
오늘날, 모든 IT 부서들에서는 적은 비용으로 더 많은 일을 하도록 강요당하고 있습니다. 이러한 환경에서 잘 통제되고 관리되는 Data Lake는 조직들이 데이터를 더 효율적으로이용하여 비즈니스 통찰력을 얻고, 올바른 의사 결정을 할 수 있도록 도와 줍니다.
Zaloni는 그림 2-1과 같이 Data Lake 구축에 대한 Best Practice를 구체화하고, 데이터 거버넌스 프레임워크 아래 동작하는 참조 아키텍처를 만들었습니다.
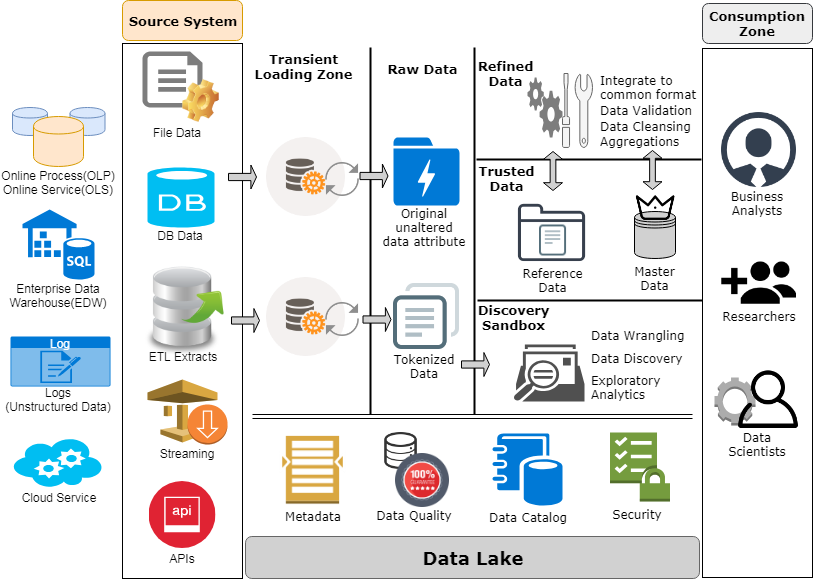
이 아키텍처의 가장 큰 장점은 온라인 트랜잭션 처리(OLTP)나 운영 데이터 저장 (ODS) 시스템, EDW, 로그나 다른 기계 데이터, 클라우드 서비스를 비롯하여 어디에서나 Data Lake에 데이터가 들어올 수 있다는 것입니다. 이러한 소스 시스템들은 파일 데이터, 데이터베이스 데이터, ETL, 스트리밍 데이터, API를 통해서 들어오는 데이터와 같은 다양한 형식을 포함합니다.
데이터는 먼저 일시적인 로딩 존에 로드 됩니다. 여기서는 Hadoop Clouster를 활용하여 MapReduce나 Spark를 통해 기본적인 데이터 품질 검사가 수행됩니다. 한번 데이터 품질 검사가 수행되고 나면, 데이터는 Raw Data Zone의 Hadoop에 로드되고, 민감한 데이터는 편집되어 개인 식별 정보(Personal Identifiable Information), 개인 건강 정보(Personal health information), 지불 카드 업계(Payment Card Industry) 정보, 다른 종류의 민감한 데이터나 취약한 데이터를 드러내지 않고 접근할 수 있습니다.
데이터 과학자와 비즈니스 분석가들은 이 Raw Data Zone을 깊이 뒤져서 데이터 집합을 찾습니다. 원하는 경우, 조직에서는 표준 데이터 정리 및 데이터 유효성 검사 방법을 수행하고, Trusted Zone에 데이터를 위치시킬 수 있습니다. 이 신뢰할 수 있는 저장소에는 마스터 데이터와 참조 데이터가 모두 들어 있습니다.
마스터 데이터는 정리되고 유효성이 검증된 기본 데이터 집합입니다. 예를 들면, Healthcare 조직에서는 기본 회원 정보(이름, 주소)와 회원의 추가 속성들(생일, 사회보장번호)가 포함된 마스터 데이터 집합을 가지고 있을 수 있습니다. 조직에서는 Change Data Capture(CDC) 메커니즘을 사용하여 이러한 Trusted Zone에 보관된 참조 데이터가 최신 정보인지 확인해야 합니다.
한편, 참조 데이터는 보다 복잡한 혼합 데이터 집합에 대한 진실된 단일 소스로 간주됩니다. 예를 들면, Healthcare 조직에서는 회원 데이터에 대한 진실된 단일 소스 데이터를 만들기 위해서 회원 기본 정보와 회원 추가 속성과 같은 마스터 데이터 저장소에 있는 여러 데이터 테이블의 정보들을 병합한 참조 데이터 집합을 가질 수 있습니다. 회원 정보를 필요로 하는 조직에 있는 누구라도 이 참조 데이터에 접근할 수 있고, 이러한 참조 데이터에 의존할 수 있음을 알 수 있습니다.
신뢰할 수 있는 영역에서, 데이터는 사용자와 데이터 과학자들의 논쟁, 발견, 탐색 분석을 위해 Discovery Sandbox(검색 샌드박스)로 이동합니다.
끝으로, Consumption Zone(소비 영역)이 있습니다. 여기서는 비즈니스 분석가들, 연구원들, 데이터 과학자들이 보고서를 만들고, "what if" 분석을 실행하고, 정보 기반 의사 결정(informed decision-making)을 위한 비즈니스 통찰력을 얻기 위해 Data Lake를 이용하여 데이터를 소비합니다.
무엇보다 중요한 것은 이 모든 것들의 밑에 메타데이터와 데이터 품질, 데이터 카탈로그와 보안을 취급하고, 모니터링하고 관리하는 통합 플랫폼이 있어야 합니다. 비록 기업마다 통합 플랫폼을 구조화하는 방법이 다양할 수 있지만, 일반적으로 거버넌스는 솔루션의 일부로 있어야만 합니다.


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/810